Jag kommer att implementera Faster R-CNN för objektdetektering i denna handledning, objektdetektering är en datorvision och bildbehandlingsteknik som används för att lokalisera instanser av objekt avseende en viss klass (bil, människa eller katt till exempel) i bilder och videoklipp.
Vid objektdetektering måste vi förutsäga kategorier för objekt och upptäcka omgivande avgränsande rutor för objekt, detta betyder att en objektdetekteringsmodell måste implementera klassificering och regression. Faster R-CNN är ett neuralt faltningsnätverk (CNN eller ConvNet) med regionförslagsnätverk (RPN). Faster R-CNN uppfanns av Shaoqing Ren, Kaiming He, Ross Girshick och Jian Sun, de förbättrade Fast R-CNN genom att skapa en RPN med nästan kostnadsfria regionförslag.
Neurala faltningsnätverk är utformade för att fungera bra med bilder, arkitekturen är inspirerad av organisationen av visuella cortex i den mänskliga hjärnan. En CNN reducerar bilder till en form som är lättare att bearbeta utan att ge avkall på förutsägbarhet. Ett RPN är ett faltningsnätverk som förutsäger objektgränser och objektpoäng samtidigt för varje enskild position.
Koden i den här handledningen är skriven i Python och koden har anpassats utifrån Faster R-CNN for Open Images Dataset by Keras. Jag har laddat ner ett urval av bilder från Open Images V5 (du kan använda den senaste versionen) och Keras Functional API används för att bygga modeller.
Ladda ner bilder
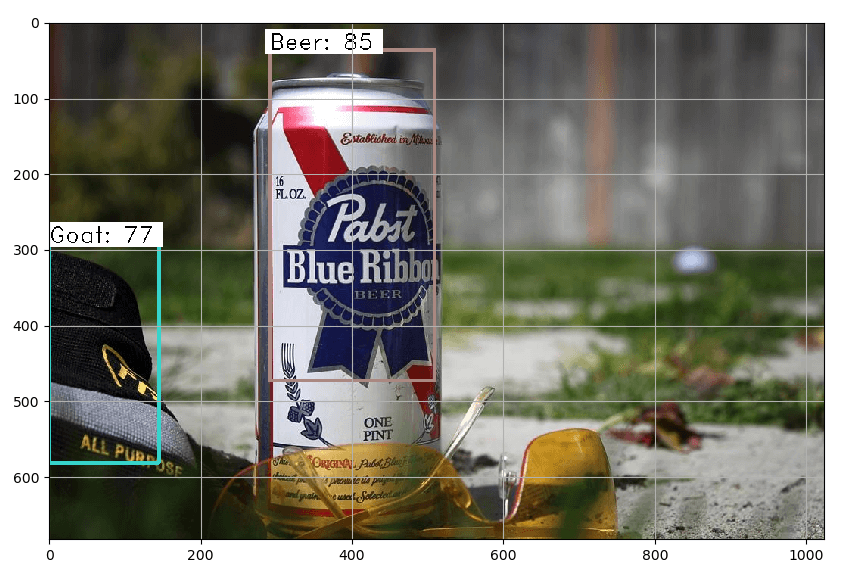
Du måste ladda ner tre .csv-filer för att kunna ladda ner ett urval av bilder från open images projektet. Navigera till Open Images Dataset och ladda ner class-descriptions-boxable.csv och train-annotations-bbox.csv, ladda ner train-images-boxable.csv från Figure Eight. Jag valde att bara använda tre kategorier (öl, bärbar dator och get) och 100 bilder i varje klass, 80 % används för träning och 20 % används för testning/validering.
# Import libraries
import numpy as np
import random
import pandas as pd
from skimage import io # scikit-image
# The main entry point for this module
def main():
# Get classes from file
classes = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\class-descriptions-boxable.csv', names=['label', 'name'])
# Get labels for Beer, Laptop and Goat
lbl_beer = classes.loc[classes['name']=='Beer', 'label'].iloc[0]
lbl_laptop = classes.loc[classes['name']=='Laptop', 'label'].iloc[0]
lbl_goat = classes.loc[classes['name']=='Goat', 'label'].iloc[0]
# Print labels
print('Beer: {0}, Laptop: {1}, Goat: {2}'.format(lbl_beer, lbl_laptop, lbl_goat))
# Load dataset of annotations
annotations = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\train-annotations-bbox.csv')
# Get objects in annotations file
beer_bbox = annotations[annotations['LabelName']==lbl_beer]
laptop_bbox = annotations[annotations['LabelName']==lbl_laptop]
goat_bbox = annotations[annotations['LabelName']==lbl_goat]
# Print counts
print('There is {0} beer in the dataset.'.format(len(beer_bbox)))
print('There is {0} laptops in the dataset.'.format(len(laptop_bbox)))
print('There is {0} goats in the dataset.'.format(len(goat_bbox)))
# Get images
beer_images = np.unique(beer_bbox['ImageID'])
laptop_images = np.unique(laptop_bbox['ImageID'])
goat_images = np.unique(goat_bbox['ImageID'])
# Print count of images
print('There are {0} images which contain beer'.format(len(beer_images)))
print('There are {0} images which contain laptops'.format(len(laptop_images)))
print('There are {0} images which contain goats'.format(len(goat_images)))
# Variables
n = 100
train_size = int(n*0.8)
base_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\'
# Pick n of each object
beers_subset = beer_images[:n]
laptops_subset = laptop_images[:n]
goats_subset = goat_images[:n]
# Load dataset of images
images = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\train-images-boxable.csv')
# Get 3 balanced subsets of images
beer_imgs_subset = [images[images['image_name']==name+'.jpg'] for name in beers_subset]
laptop_imgs_subset = [images[images['image_name']==name+'.jpg'] for name in laptops_subset]
goat_imgs_subset = [images[images['image_name']==name+'.jpg'] for name in goats_subset]
# Download images
for i in range(n):
beer_img = io.imread(beer_imgs_subset[i]['image_url'].values[0])
laptop_img = io.imread(laptop_imgs_subset[i]['image_url'].values[0])
goat_img = io.imread(goat_imgs_subset[i]['image_url'].values[0])
if(i < train_size):
io.imsave(base_path + 'train\\' + beer_imgs_subset[i]['image_name'].values[0], beer_img)
io.imsave(base_path + 'train\\' + laptop_imgs_subset[i]['image_name'].values[0], laptop_img)
io.imsave(base_path + 'train\\' + goat_imgs_subset[i]['image_name'].values[0], goat_img)
else:
io.imsave(base_path + 'test\\' + beer_imgs_subset[i]['image_name'].values[0], beer_img)
io.imsave(base_path + 'test\\' + laptop_imgs_subset[i]['image_name'].values[0], laptop_img)
io.imsave(base_path + 'test\\' + goat_imgs_subset[i]['image_name'].values[0], goat_img)
# Tell python to run main method
if __name__ == "__main__": main()Skapa annotationer
Jag har laddat ner bilder och nu är det dags att skapa annotationsfiler, en för träning och en för att testning. Annotationsfiler berättar om objektens placering i bilder. Dessa filer visar filnamn, avgränsningsrutor och klassnamn för varje fil och objekt. En bild kan innehålla många objekt.
# Import libraries
import os
import cv2
import pandas as pd
# Create an annotations file
def create_annotation_file(base_path, annotations, classes, labels, mode='train'):
# Create a dataframe
df = pd.DataFrame(columns=['filename', 'xmin', 'ymin', 'xmax', 'ymax', 'class'])
# Get all images
images = os.listdir(base_path + mode)
# Loop images
for i in range(len(images)):
img_name = images[i]
img_id = img_name.split('.')[0]
tmp_df = annotations[annotations['ImageID']==img_id]
img = cv2.imread((base_path + mode + '\\' + img_name))
height, width = img.shape[:2]
for index, row in tmp_df.iterrows():
label_name = row['LabelName']
for i in range(len(labels)):
if label_name == labels[i]:
df = df.append({
'filename': mode + '\\' + img_name,
'xmin': int(row['XMin'] * width),
'ymin': int(row['YMin'] * height),
'xmax': int(row['XMax'] * width),
'ymax': int(row['YMax'] * height),
'class': classes[i]},
ignore_index=True)
# Save annotations file
df.to_csv(base_path + mode + '_annotations.csv', index=None, header=False)
# The main entry point for this module
def main():
# Variables
base_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\'
classes = ['Beer', 'Laptop', 'Goat']
labels = ['/m/01599', '/m/01c648', '/m/03fwl']
# Load dataset of annotations
annotations = pd.read_csv('C:\\DATA\\Python-data\\open-images-v5\\train-annotations-bbox.csv')
# Create annotation files for train and test
create_annotation_file(base_path, annotations, classes, labels, mode='train')
create_annotation_file(base_path, annotations, classes, labels, mode='test')
# Tell python to run main method
if __name__ == "__main__": main()Gemensamma metoder
Den här modulen innehåller många praktiska metoder som används vid träning och utvärdering, modulen har en klass för konfiguration och några bildmetoder.
# Import libraries
import sys
import math
import cv2
import copy
import random
import keras
import numpy as np
import tensorflow as tf
# Minimum tensorflow version
MINIMUM_TF_VERSION = 1, 12, 0
# Restrict tensortlow to only use the one GPU
def setup_gpu(gpu_id):
if tf_version_ok((2, 0, 0)):
if gpu_id == 'cpu' or gpu_id == -1:
tf.config.experimental.set_visible_devices([], 'GPU')
return
# Get all gpus
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
# Restrict TensorFlow to only use the first GPU.
try:
# Currently, memory growth needs to be the same across GPUs.
for gpu in gpus:
#tf.config.experimental.set_virtual_device_configuration(gpu, [tf.config.experimental.VirtualDeviceConfiguration(memory_limit=4096)])
tf.config.experimental.set_memory_growth(gpu, True)
# Use only the selcted gpu.
tf.config.experimental.set_visible_devices(gpus[gpu_id], 'GPU')
except RuntimeError as e:
# Visible devices must be set before GPUs have been initialized.
print(e)
logical_gpus = tf.config.experimental.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
else:
import os
if gpu_id == 'cpu' or gpu_id == -1:
os.environ['CUDA_VISIBLE_DEVICES'] = ""
return
os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_id)
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.5
config.gpu_options.allow_growth = True
tf.keras.backend.set_session(tf.Session(config=config))
# Get the Tensorflow version
def tf_version():
return tuple(map(int, tf.version.VERSION.split('-')[0].split('.')))
# Check if the current Tensorflow version is higher than the minimum version
def tf_version_ok(minimum_tf_version=MINIMUM_TF_VERSION):
return tf_version() >= minimum_tf_version
# This class is used for configuration
class Config:
# Initializes the class
def __init__(self):
# Print the process or not
self.verbose = True
# Settings for data augmentation
self.use_horizontal_flips = False
self.use_vertical_flips = False
self.rot_90 = False
# Anchor box scales
# Note that if im_size is smaller, anchor_box_scales should be scaled
# Original anchor_box_scales in the paper is [128, 256, 512]
self.anchor_box_scales = [64, 128, 256]
# Anchor box ratios
self.anchor_box_ratios = [[1, 1], [1./math.sqrt(2), 2./math.sqrt(2)], [2./math.sqrt(2), 1./math.sqrt(2)]]
# Size to resize the smallest side of the image
# Original setting in paper is 600. Set to 300 in here to save training time
self.im_size = 300
# image channel-wise mean to subtract
self.img_channel_mean = [103.939, 116.779, 123.68]
self.img_scaling_factor = 1.0
# number of ROIs at once
self.num_rois = 4
# stride at the RPN (this depends on the network configuration)
self.rpn_stride = 16
# scaling the stdev
self.std_scaling = 4.0
self.classifier_regr_std = [8.0, 8.0, 4.0, 4.0]
# overlaps for RPN
self.rpn_min_overlap = 0.3
self.rpn_max_overlap = 0.7
# overlaps for classifier ROIs
self.classifier_min_overlap = 0.1
self.classifier_max_overlap = 0.5
# Loss function settings
self.lambda_rpn_regr = 1.0
self.lambda_rpn_class = 1.0
self.lambda_cls_regr = 1.0
self.lambda_cls_class = 1.0
self.epsilon = 1e-4
# Paths
self.annotations_file_path = None
self.img_base_path = None
self.pretrained_model_path = None
self.model_path = None
self.records_path = None
# Parse the data from annotation file
def get_data(config):
# Make sure that there is configurations
if config == None:
config = Config()
# Variables
found_bg = False
all_imgs = {}
classes_count = {}
class_mapping = {}
visualise = True
i = 1
with open(config.annotations_file_path,'r') as f:
print('Parsing annotation file')
for line in f:
# Print process
sys.stdout.write('\r'+'idx=' + str(i))
i += 1
line_split = line.strip().split(',')
# Make sure the info saved in annotation file matching the format (path_filename, x1, y1, x2, y2, class_name)
(filename,x1,y1,x2,y2,class_name) = line_split
if class_name not in classes_count:
classes_count[class_name] = 1
else:
classes_count[class_name] += 1
if class_name not in class_mapping:
if class_name == 'bg' and found_bg == False:
print('Found class name with special name bg. Will be treated as a background region (this is usually for hard negative mining).')
found_bg = True
class_mapping[class_name] = len(class_mapping)
if filename not in all_imgs:
all_imgs[filename] = {}
img = cv2.imread(config.img_base_path + filename)
(rows,cols) = img.shape[:2]
all_imgs[filename]['filepath'] = filename
all_imgs[filename]['width'] = cols
all_imgs[filename]['height'] = rows
all_imgs[filename]['bboxes'] = []
all_imgs[filename]['bboxes'].append({'class': class_name, 'x1': int(x1), 'x2': int(x2), 'y1': int(y1), 'y2': int(y2)})
all_data = []
for key in all_imgs:
all_data.append(all_imgs[key])
# make sure the bg class is last in the list
if found_bg:
if class_mapping['bg'] != len(class_mapping) - 1:
key_to_switch = [key for key in class_mapping.keys() if class_mapping[key] == len(class_mapping)-1][0]
val_to_switch = class_mapping['bg']
class_mapping['bg'] = len(class_mapping) - 1
class_mapping[key_to_switch] = val_to_switch
return all_data, classes_count, class_mapping
# Loss function for rpn regression
def rpn_loss_regr(num_anchors, config=None):
# Make sure that there is configurations
if config == None:
config = Config()
def rpn_loss_regr_fixed_num(y_true, y_pred):
# x is the difference between true value and predicted vaue
x = y_true[:, :, :, 4 * num_anchors:] - y_pred
# absolute value of x
x_abs = keras.backend.abs(x)
# If x_abs <= 1.0, x_bool = 1
x_bool = keras.backend.cast(keras.backend.less_equal(x_abs, 1.0), tf.float32)
return config.lambda_rpn_regr * keras.backend.sum(
y_true[:, :, :, :4 * num_anchors] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / keras.backend.sum(config.epsilon + y_true[:, :, :, :4 * num_anchors])
return rpn_loss_regr_fixed_num
# Loss function for rpn classification
def rpn_loss_cls(num_anchors, config=None):
# Make sure that there is configurations
if config == None:
config = Config()
def rpn_loss_cls_fixed_num(y_true, y_pred):
return config.lambda_rpn_class * keras.backend.sum(y_true[:, :, :, :num_anchors] * keras.backend.binary_crossentropy(y_pred[:, :, :, :], y_true[:, :, :, num_anchors:])) / keras.backend.sum(config.epsilon + y_true[:, :, :, :num_anchors])
# Return a function
return rpn_loss_cls_fixed_num
# Loss function for rpn regression
def class_loss_regr(num_classes, config=None):
# Make sure that there is configurations
if config == None:
config = Config()
def class_loss_regr_fixed_num(y_true, y_pred):
x = y_true[:, :, 4*num_classes:] - y_pred
x_abs = keras.backend.abs(x)
x_bool = keras.backend.cast(keras.backend.less_equal(x_abs, 1.0), 'float32')
return config.lambda_cls_regr * keras.backend.sum(y_true[:, :, :4*num_classes] * (x_bool * (0.5 * x * x) + (1 - x_bool) * (x_abs - 0.5))) / keras.backend.sum(config.epsilon + y_true[:, :, :4*num_classes])
# Return a function
return class_loss_regr_fixed_num
# Loss function for classification y_true, y_pred,
def class_loss_cls(config=None):
# Make sure that there is configurations
if config == None:
config = Config()
def class_loss_cls_fixed_num(y_true, y_pred):
return config.lambda_cls_class * keras.backend.mean(keras.losses.categorical_crossentropy(y_true[0, :, :], y_pred[0, :, :]))
# Return a function
return class_loss_cls_fixed_num
# Get image output length
def get_img_output_length(width, height):
def get_output_length(input_length):
return input_length//16
# Return output length for width and height
return get_output_length(width), get_output_length(height)
# Get a new image size
def get_new_img_size(width, height, img_min_side=300):
if width <= height:
f = float(img_min_side) / width
resized_height = int(f * height)
resized_width = img_min_side
else:
f = float(img_min_side) / height
resized_width = int(f * width)
resized_height = img_min_side
# Return resized width and height
return resized_width, resized_height
# Augument
def augment(img_data, config, augment=True):
assert 'filepath' in img_data
assert 'bboxes' in img_data
assert 'width' in img_data
assert 'height' in img_data
img_data_aug = copy.deepcopy(img_data)
img = cv2.imread(config.img_base_path + img_data_aug['filepath'])
if augment:
rows, cols = img.shape[:2]
if config.use_horizontal_flips and np.random.randint(0, 2) == 0:
img = cv2.flip(img, 1)
for bbox in img_data_aug['bboxes']:
x1 = bbox['x1']
x2 = bbox['x2']
bbox['x2'] = cols - x1
bbox['x1'] = cols - x2
if config.use_vertical_flips and np.random.randint(0, 2) == 0:
img = cv2.flip(img, 0)
for bbox in img_data_aug['bboxes']:
y1 = bbox['y1']
y2 = bbox['y2']
bbox['y2'] = rows - y1
bbox['y1'] = rows - y2
if config.rot_90:
angle = np.random.choice([0,90,180,270],1)[0]
if angle == 270:
img = np.transpose(img, (1,0,2))
img = cv2.flip(img, 0)
elif angle == 180:
img = cv2.flip(img, -1)
elif angle == 90:
img = np.transpose(img, (1,0,2))
img = cv2.flip(img, 1)
elif angle == 0:
pass
for bbox in img_data_aug['bboxes']:
x1 = bbox['x1']
x2 = bbox['x2']
y1 = bbox['y1']
y2 = bbox['y2']
if angle == 270:
bbox['x1'] = y1
bbox['x2'] = y2
bbox['y1'] = cols - x2
bbox['y2'] = cols - x1
elif angle == 180:
bbox['x2'] = cols - x1
bbox['x1'] = cols - x2
bbox['y2'] = rows - y1
bbox['y1'] = rows - y2
elif angle == 90:
bbox['x1'] = rows - y2
bbox['x2'] = rows - y1
bbox['y1'] = x1
bbox['y2'] = x2
elif angle == 0:
pass
img_data_aug['width'] = img.shape[1]
img_data_aug['height'] = img.shape[0]
return img_data_aug, img
# Yield the ground-truth anchors as Y (labels)
def get_anchor_gt(all_img_data, config, mode='train'):
while True:
for img_data in all_img_data:
try:
# read in image, and optionally add augmentation
if mode == 'train':
img_data_aug, x_img = augment(img_data, config, augment=True)
else:
img_data_aug, x_img = augment(img_data, config, augment=False)
(width, height) = (img_data_aug['width'], img_data_aug['height'])
(rows, cols, _) = x_img.shape
assert cols == width
assert rows == height
# get image dimensions for resizing
(resized_width, resized_height) = get_new_img_size(width, height, config.im_size)
# resize the image so that smalles side is length = 300px
x_img = cv2.resize(x_img, (resized_width, resized_height), interpolation=cv2.INTER_CUBIC)
debug_img = x_img.copy()
try:
y_rpn_cls, y_rpn_regr, num_pos = calc_rpn(config, img_data_aug, width, height, resized_width, resized_height)
except Exception as e:
print(e)
continue
# Zero-center by mean pixel, and preprocess image
x_img = x_img[:,:, (2, 1, 0)] # BGR -> RGB
x_img = x_img.astype(np.float32)
x_img[:, :, 0] -= config.img_channel_mean[0]
x_img[:, :, 1] -= config.img_channel_mean[1]
x_img[:, :, 2] -= config.img_channel_mean[2]
x_img /= config.img_scaling_factor
x_img = np.transpose(x_img, (2, 0, 1))
x_img = np.expand_dims(x_img, axis=0)
y_rpn_regr[:, y_rpn_regr.shape[1]//2:, :, :] *= config.std_scaling
x_img = np.transpose(x_img, (0, 2, 3, 1))
y_rpn_cls = np.transpose(y_rpn_cls, (0, 2, 3, 1))
y_rpn_regr = np.transpose(y_rpn_regr, (0, 2, 3, 1))
yield np.copy(x_img), [np.copy(y_rpn_cls), np.copy(y_rpn_regr)], img_data_aug, debug_img, num_pos
except Exception as e:
print(e)
continue
# Calculate union
def union(au, bu, area_intersection):
area_a = (au[2] - au[0]) * (au[3] - au[1])
area_b = (bu[2] - bu[0]) * (bu[3] - bu[1])
area_union = area_a + area_b - area_intersection
return area_union
# Calculate intersection
def intersection(ai, bi):
x = max(ai[0], bi[0])
y = max(ai[1], bi[1])
w = min(ai[2], bi[2]) - x
h = min(ai[3], bi[3]) - y
if w < 0 or h < 0:
return 0
return w*h
# Calculate IOU
def iou(a, b):
# a and b should be (x1,y1,x2,y2)
if a[0] >= a[2] or a[1] >= a[3] or b[0] >= b[2] or b[1] >= b[3]:
return 0.0
area_i = intersection(a, b)
area_u = union(a, b, area_i)
return float(area_i) / float(area_u + 1e-6)
# Calculate the rpn for all anchors
def calc_rpn(config, img_data, width, height, resized_width, resized_height):
downscale = float(config.rpn_stride)
anchor_sizes = config.anchor_box_scales
anchor_ratios = config.anchor_box_ratios
num_anchors = len(anchor_sizes) * len(anchor_ratios)
# calculate the output map size based on the network architecture
(output_width, output_height) = get_img_output_length(resized_width, resized_height)
n_anchratios = len(anchor_ratios)
# initialise empty output objectives
y_rpn_overlap = np.zeros((output_height, output_width, num_anchors))
y_is_box_valid = np.zeros((output_height, output_width, num_anchors))
y_rpn_regr = np.zeros((output_height, output_width, num_anchors * 4))
num_bboxes = len(img_data['bboxes'])
num_anchors_for_bbox = np.zeros(num_bboxes).astype(int)
best_anchor_for_bbox = -1*np.ones((num_bboxes, 4)).astype(int)
best_iou_for_bbox = np.zeros(num_bboxes).astype(np.float32)
best_x_for_bbox = np.zeros((num_bboxes, 4)).astype(int)
best_dx_for_bbox = np.zeros((num_bboxes, 4)).astype(np.float32)
# get the GT box coordinates, and resize to account for image resizing
gta = np.zeros((num_bboxes, 4))
for bbox_num, bbox in enumerate(img_data['bboxes']):
# get the GT box coordinates, and resize to account for image resizing
gta[bbox_num, 0] = bbox['x1'] * (resized_width / float(width))
gta[bbox_num, 1] = bbox['x2'] * (resized_width / float(width))
gta[bbox_num, 2] = bbox['y1'] * (resized_height / float(height))
gta[bbox_num, 3] = bbox['y2'] * (resized_height / float(height))
# rpn ground truth
for anchor_size_idx in range(len(anchor_sizes)):
for anchor_ratio_idx in range(n_anchratios):
anchor_x = anchor_sizes[anchor_size_idx] * anchor_ratios[anchor_ratio_idx][0]
anchor_y = anchor_sizes[anchor_size_idx] * anchor_ratios[anchor_ratio_idx][1]
for ix in range(output_width):
# x-coordinates of the current anchor box
x1_anc = downscale * (ix + 0.5) - anchor_x / 2
x2_anc = downscale * (ix + 0.5) + anchor_x / 2
# ignore boxes that go across image boundaries
if x1_anc < 0 or x2_anc > resized_width:
continue
for jy in range(output_height):
# y-coordinates of the current anchor box
y1_anc = downscale * (jy + 0.5) - anchor_y / 2
y2_anc = downscale * (jy + 0.5) + anchor_y / 2
# ignore boxes that go across image boundaries
if y1_anc < 0 or y2_anc > resized_height:
continue
# bbox_type indicates whether an anchor should be a target
# Initialize with 'negative'
bbox_type = 'neg'
# this is the best IOU for the (x,y) coord and the current anchor
# note that this is different from the best IOU for a GT bbox
best_iou_for_loc = 0.0
for bbox_num in range(num_bboxes):
# get IOU of the current GT box and the current anchor box
curr_iou = iou([gta[bbox_num, 0], gta[bbox_num, 2], gta[bbox_num, 1], gta[bbox_num, 3]], [x1_anc, y1_anc, x2_anc, y2_anc])
# calculate the regression targets if they will be needed
if curr_iou > best_iou_for_bbox[bbox_num] or curr_iou > config.rpn_max_overlap:
cx = (gta[bbox_num, 0] + gta[bbox_num, 1]) / 2.0
cy = (gta[bbox_num, 2] + gta[bbox_num, 3]) / 2.0
cxa = (x1_anc + x2_anc)/2.0
cya = (y1_anc + y2_anc)/2.0
# x,y are the center point of ground-truth bbox
# xa,ya are the center point of anchor bbox (xa=downscale * (ix + 0.5); ya=downscale * (iy+0.5))
# w,h are the width and height of ground-truth bbox
# wa,ha are the width and height of anchor bboxe
# tx = (x - xa) / wa
# ty = (y - ya) / ha
# tw = log(w / wa)
# th = log(h / ha)
tx = (cx - cxa) / (x2_anc - x1_anc)
ty = (cy - cya) / (y2_anc - y1_anc)
tw = np.log((gta[bbox_num, 1] - gta[bbox_num, 0]) / (x2_anc - x1_anc))
th = np.log((gta[bbox_num, 3] - gta[bbox_num, 2]) / (y2_anc - y1_anc))
if img_data['bboxes'][bbox_num]['class'] != 'bg':
# all GT boxes should be mapped to an anchor box, so we keep track of which anchor box was best
if curr_iou > best_iou_for_bbox[bbox_num]:
best_anchor_for_bbox[bbox_num] = [jy, ix, anchor_ratio_idx, anchor_size_idx]
best_iou_for_bbox[bbox_num] = curr_iou
best_x_for_bbox[bbox_num,:] = [x1_anc, x2_anc, y1_anc, y2_anc]
best_dx_for_bbox[bbox_num,:] = [tx, ty, tw, th]
# we set the anchor to positive if the IOU is >0.7 (it does not matter if there was another better box, it just indicates overlap)
if curr_iou > config.rpn_max_overlap:
bbox_type = 'pos'
num_anchors_for_bbox[bbox_num] += 1
# we update the regression layer target if this IOU is the best for the current (x,y) and anchor position
if curr_iou > best_iou_for_loc:
best_iou_for_loc = curr_iou
best_regr = (tx, ty, tw, th)
# if the IOU is >0.3 and <0.7, it is ambiguous and no included in the objective
if config.rpn_min_overlap < curr_iou < config.rpn_max_overlap:
# gray zone between neg and pos
if bbox_type != 'pos':
bbox_type = 'neutral'
# turn on or off outputs depending on IOUs
if bbox_type == 'neg':
y_is_box_valid[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 1
y_rpn_overlap[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 0
elif bbox_type == 'neutral':
y_is_box_valid[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 0
y_rpn_overlap[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 0
elif bbox_type == 'pos':
y_is_box_valid[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 1
y_rpn_overlap[jy, ix, anchor_ratio_idx + n_anchratios * anchor_size_idx] = 1
start = 4 * (anchor_ratio_idx + n_anchratios * anchor_size_idx)
y_rpn_regr[jy, ix, start:start+4] = best_regr
# we ensure that every bbox has at least one positive RPN region
for idx in range(num_anchors_for_bbox.shape[0]):
if num_anchors_for_bbox[idx] == 0:
# no box with an IOU greater than zero ...
if best_anchor_for_bbox[idx, 0] == -1:
continue
y_is_box_valid[
best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], best_anchor_for_bbox[idx,2] + n_anchratios *
best_anchor_for_bbox[idx,3]] = 1
y_rpn_overlap[
best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], best_anchor_for_bbox[idx,2] + n_anchratios *
best_anchor_for_bbox[idx,3]] = 1
start = 4 * (best_anchor_for_bbox[idx,2] + n_anchratios * best_anchor_for_bbox[idx,3])
y_rpn_regr[
best_anchor_for_bbox[idx,0], best_anchor_for_bbox[idx,1], start:start+4] = best_dx_for_bbox[idx, :]
y_rpn_overlap = np.transpose(y_rpn_overlap, (2, 0, 1))
y_rpn_overlap = np.expand_dims(y_rpn_overlap, axis=0)
y_is_box_valid = np.transpose(y_is_box_valid, (2, 0, 1))
y_is_box_valid = np.expand_dims(y_is_box_valid, axis=0)
y_rpn_regr = np.transpose(y_rpn_regr, (2, 0, 1))
y_rpn_regr = np.expand_dims(y_rpn_regr, axis=0)
pos_locs = np.where(np.logical_and(y_rpn_overlap[0, :, :, :] == 1, y_is_box_valid[0, :, :, :] == 1))
neg_locs = np.where(np.logical_and(y_rpn_overlap[0, :, :, :] == 0, y_is_box_valid[0, :, :, :] == 1))
num_pos = len(pos_locs[0])
# one issue is that the RPN has many more negative than positive regions, so we turn off some of the negative
# regions. We also limit it to 256 regions.
num_regions = 256
if len(pos_locs[0]) > num_regions/2:
val_locs = random.sample(range(len(pos_locs[0])), len(pos_locs[0]) - num_regions/2)
y_is_box_valid[0, pos_locs[0][val_locs], pos_locs[1][val_locs], pos_locs[2][val_locs]] = 0
num_pos = num_regions/2
if len(neg_locs[0]) + num_pos > num_regions:
val_locs = random.sample(range(len(neg_locs[0])), len(neg_locs[0]) - num_pos)
y_is_box_valid[0, neg_locs[0][val_locs], neg_locs[1][val_locs], neg_locs[2][val_locs]] = 0
y_rpn_cls = np.concatenate([y_is_box_valid, y_rpn_overlap], axis=1)
y_rpn_regr = np.concatenate([np.repeat(y_rpn_overlap, 4, axis=1), y_rpn_regr], axis=1)
return np.copy(y_rpn_cls), np.copy(y_rpn_regr), num_pos
# Non max suppression: http://www.pyimagesearch.com/2015/02/16/faster-non-maximum-suppression-python/
def non_max_suppression_fast(boxes, probs, overlap_thresh=0.9, max_boxes=300):
# if there are no boxes, return an empty list
if len(boxes) == 0:
return []
# grab the coordinates of the bounding boxes
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
np.testing.assert_array_less(x1, x2)
np.testing.assert_array_less(y1, y2)
# if the bounding boxes integers, convert them to floats --
# this is important since we'll be doing a bunch of divisions
if boxes.dtype.kind == "i":
boxes = boxes.astype("float")
# initialize the list of picked indexes
pick = []
# calculate the areas
area = (x2 - x1) * (y2 - y1)
# sort the bounding boxes
idxs = np.argsort(probs)
# keep looping while some indexes still remain in the indexes
# list
while len(idxs) > 0:
# grab the last index in the indexes list and add the
# index value to the list of picked indexes
last = len(idxs) - 1
i = idxs[last]
pick.append(i)
# find the intersection
xx1_int = np.maximum(x1[i], x1[idxs[:last]])
yy1_int = np.maximum(y1[i], y1[idxs[:last]])
xx2_int = np.minimum(x2[i], x2[idxs[:last]])
yy2_int = np.minimum(y2[i], y2[idxs[:last]])
ww_int = np.maximum(0, xx2_int - xx1_int)
hh_int = np.maximum(0, yy2_int - yy1_int)
area_int = ww_int * hh_int
# find the union
area_union = area[i] + area[idxs[:last]] - area_int
# compute the ratio of overlap
overlap = area_int/(area_union + 1e-6)
# delete all indexes from the index list that have
idxs = np.delete(idxs, np.concatenate(([last],
np.where(overlap > overlap_thresh)[0])))
if len(pick) >= max_boxes:
break
# return only the bounding boxes that were picked using the integer data type
boxes = boxes[pick].astype("int")
probs = probs[pick]
return boxes, probs
# Converts from (x1,y1,x2,y2) to (x,y,w,h) format
def calc_iou(R, img_data, config, class_mapping):
bboxes = img_data['bboxes']
(width, height) = (img_data['width'], img_data['height'])
# get image dimensions for resizing
(resized_width, resized_height) = get_new_img_size(width, height, config.im_size)
gta = np.zeros((len(bboxes), 4))
for bbox_num, bbox in enumerate(bboxes):
# get the GT box coordinates, and resize to account for image resizing
# gta[bbox_num, 0] = (40 * (600 / 800)) / 16 = int(round(1.875)) = 2 (x in feature map)
gta[bbox_num, 0] = int(round(bbox['x1'] * (resized_width / float(width))/config.rpn_stride))
gta[bbox_num, 1] = int(round(bbox['x2'] * (resized_width / float(width))/config.rpn_stride))
gta[bbox_num, 2] = int(round(bbox['y1'] * (resized_height / float(height))/config.rpn_stride))
gta[bbox_num, 3] = int(round(bbox['y2'] * (resized_height / float(height))/config.rpn_stride))
x_roi = []
y_class_num = []
y_class_regr_coords = []
y_class_regr_label = []
IoUs = [] # for debugging only
# R.shape[0]: number of bboxes (=300 from non_max_suppression)
for ix in range(R.shape[0]):
(x1, y1, x2, y2) = R[ix, :]
x1 = int(round(x1))
y1 = int(round(y1))
x2 = int(round(x2))
y2 = int(round(y2))
best_iou = 0.0
best_bbox = -1
# Iterate through all the ground-truth bboxes to calculate the iou
for bbox_num in range(len(bboxes)):
curr_iou = iou([gta[bbox_num, 0], gta[bbox_num, 2], gta[bbox_num, 1], gta[bbox_num, 3]], [x1, y1, x2, y2])
# Find out the corresponding ground-truth bbox_num with larget iou
if curr_iou > best_iou:
best_iou = curr_iou
best_bbox = bbox_num
if best_iou < config.classifier_min_overlap:
continue
else:
w = x2 - x1
h = y2 - y1
x_roi.append([x1, y1, w, h])
IoUs.append(best_iou)
if config.classifier_min_overlap <= best_iou < config.classifier_max_overlap:
# hard negative example
cls_name = 'bg'
elif config.classifier_max_overlap <= best_iou:
cls_name = bboxes[best_bbox]['class']
cxg = (gta[best_bbox, 0] + gta[best_bbox, 1]) / 2.0
cyg = (gta[best_bbox, 2] + gta[best_bbox, 3]) / 2.0
cx = x1 + w / 2.0
cy = y1 + h / 2.0
tx = (cxg - cx) / float(w)
ty = (cyg - cy) / float(h)
tw = np.log((gta[best_bbox, 1] - gta[best_bbox, 0]) / float(w))
th = np.log((gta[best_bbox, 3] - gta[best_bbox, 2]) / float(h))
else:
print('roi = {}'.format(best_iou))
raise RuntimeError
class_num = class_mapping[cls_name]
class_label = len(class_mapping) * [0]
class_label[class_num] = 1
y_class_num.append(copy.deepcopy(class_label))
coords = [0] * 4 * (len(class_mapping) - 1)
labels = [0] * 4 * (len(class_mapping) - 1)
if cls_name != 'bg':
label_pos = 4 * class_num
sx, sy, sw, sh = config.classifier_regr_std
coords[label_pos:4+label_pos] = [sx*tx, sy*ty, sw*tw, sh*th]
labels[label_pos:4+label_pos] = [1, 1, 1, 1]
y_class_regr_coords.append(copy.deepcopy(coords))
y_class_regr_label.append(copy.deepcopy(labels))
else:
y_class_regr_coords.append(copy.deepcopy(coords))
y_class_regr_label.append(copy.deepcopy(labels))
if len(x_roi) == 0:
return None, None, None, None
# bboxes that iou > config.classifier_min_overlap for all gt bboxes in 300 non_max_suppression bboxes
X = np.array(x_roi)
# one hot code for bboxes from above => x_roi (X)
Y1 = np.array(y_class_num)
# corresponding labels and corresponding gt bboxes
Y2 = np.concatenate([np.array(y_class_regr_label),np.array(y_class_regr_coords)],axis=1)
return np.expand_dims(X, axis=0), np.expand_dims(Y1, axis=0), np.expand_dims(Y2, axis=0), IoUs
# Formats the image size based on config
def format_img_size(img, config):
img_min_side = float(config.im_size)
(height,width,_) = img.shape
if width <= height:
ratio = img_min_side/width
new_height = int(ratio * height)
new_width = int(img_min_side)
else:
ratio = img_min_side/height
new_width = int(ratio * width)
new_height = int(img_min_side)
img = cv2.resize(img, (new_width, new_height), interpolation=cv2.INTER_CUBIC)
return img, ratio
# Formats the image channels based on config
def format_img_channels(img, config):
img = img[:, :, (2, 1, 0)]
img = img.astype(np.float32)
img[:, :, 0] -= config.img_channel_mean[0]
img[:, :, 1] -= config.img_channel_mean[1]
img[:, :, 2] -= config.img_channel_mean[2]
img /= config.img_scaling_factor
img = np.transpose(img, (2, 0, 1))
img = np.expand_dims(img, axis=0)
return img
# Formats an image for model prediction based on config
def format_img(img, config):
img, ratio = format_img_size(img, config)
img = format_img_channels(img, config)
return img, ratio
# Method to transform the coordinates of the bounding box to its original size
def get_real_coordinates(ratio, x1, y1, x2, y2):
real_x1 = int(round(x1 // ratio))
real_y1 = int(round(y1 // ratio))
real_x2 = int(round(x2 // ratio))
real_y2 = int(round(y2 // ratio))
return (real_x1, real_y1, real_x2 ,real_y2)
# Get map
def get_map(pred, gt, f):
T = {}
P = {}
fx, fy = f
for bbox in gt:
bbox['bbox_matched'] = False
pred_probs = np.array([s['prob'] for s in pred])
box_idx_sorted_by_prob = np.argsort(pred_probs)[::-1]
for box_idx in box_idx_sorted_by_prob:
pred_box = pred[box_idx]
pred_class = pred_box['class']
pred_x1 = pred_box['x1']
pred_x2 = pred_box['x2']
pred_y1 = pred_box['y1']
pred_y2 = pred_box['y2']
pred_prob = pred_box['prob']
if pred_class not in P:
P[pred_class] = []
T[pred_class] = []
P[pred_class].append(pred_prob)
found_match = False
for gt_box in gt:
gt_class = gt_box['class']
gt_x1 = gt_box['x1']/fx
gt_x2 = gt_box['x2']/fx
gt_y1 = gt_box['y1']/fy
gt_y2 = gt_box['y2']/fy
gt_seen = gt_box['bbox_matched']
if gt_class != pred_class:
continue
if gt_seen:
continue
iou_map = iou((pred_x1, pred_y1, pred_x2, pred_y2), (gt_x1, gt_y1, gt_x2, gt_y2))
if iou_map >= 0.5:
found_match = True
gt_box['bbox_matched'] = True
break
else:
continue
T[pred_class].append(int(found_match))
for gt_box in gt:
if not gt_box['bbox_matched']:# and not gt_box['difficult']:
if gt_box['class'] not in P:
P[gt_box['class']] = []
T[gt_box['class']] = []
T[gt_box['class']].append(1)
P[gt_box['class']].append(0)
#import pdb
#pdb.set_trace()
return T, P
# Format image for map. Resize original image to config.im_size (300 in here)
def format_img_map(img, config):
img_min_side = float(config.im_size)
(height,width,_) = img.shape
if width <= height:
f = img_min_side/width
new_height = int(f * height)
new_width = int(img_min_side)
else:
f = img_min_side/height
new_width = int(f * width)
new_height = int(img_min_side)
fx = width/float(new_width)
fy = height/float(new_height)
img = cv2.resize(img, (new_width, new_height), interpolation=cv2.INTER_CUBIC)
# Change image channel from BGR to RGB
img = img[:, :, (2, 1, 0)]
img = img.astype(np.float32)
img[:, :, 0] -= config.img_channel_mean[0]
img[:, :, 1] -= config.img_channel_mean[1]
img[:, :, 2] -= config.img_channel_mean[2]
img /= config.img_scaling_factor
# Change img shape from (height, width, channel) to (channel, height, width)
img = np.transpose(img, (2, 0, 1))
# Expand one dimension at axis 0
# img shape becames (1, channel, height, width)
img = np.expand_dims(img, axis=0)
return img, fx, fyLager
Den här modulen innehåller anpassade lager som används av modellbyggaren för att skapa en Faster R-CNN-modell.
# Import libraries
import cv2
import keras
import math
import numpy as np
import tensorflow as tf
import annytab.frcnn.common as common
# ROI pooling layer for 2D inputs
# K. He, X. Zhang, S. Ren, J. Sun
class RoiPoolingConv(keras.engine.Layer):
def __init__(self, pool_size, num_rois, **kwargs):
# keras.backend.image_dim_ordering()
self.dim_ordering = keras.backend.image_data_format()
self.pool_size = pool_size
self.num_rois = num_rois
super(RoiPoolingConv, self).__init__(**kwargs)
def build(self, input_shape):
self.nb_channels = input_shape[0][3]
def compute_output_shape(self, input_shape):
return None, self.num_rois, self.pool_size, self.pool_size, self.nb_channels
def call(self, x, mask=None):
assert(len(x) == 2)
# x[0] is image with shape (rows, cols, channels)
img = x[0]
# x[1] is roi with shape (num_rois,4) with ordering (x,y,w,h)
rois = x[1]
input_shape = keras.backend.shape(img)
outputs = []
for roi_idx in range(self.num_rois):
x = rois[0, roi_idx, 0]
y = rois[0, roi_idx, 1]
w = rois[0, roi_idx, 2]
h = rois[0, roi_idx, 3]
x = keras.backend.cast(x, 'int32')
y = keras.backend.cast(y, 'int32')
w = keras.backend.cast(w, 'int32')
h = keras.backend.cast(h, 'int32')
# Resized roi of the image to pooling size (7x7)
# tf.image.resize_images
rs = tf.image.resize(img[:, y:y+h, x:x+w, :], (self.pool_size, self.pool_size))
outputs.append(rs)
# Concentate tensors along an axis
final_output = keras.backend.concatenate(outputs, axis=0)
# Reshape to (1, num_rois, pool_size, pool_size, nb_channels)
# Might be (1, 4, 7, 7, 3)
final_output = keras.backend.reshape(final_output, (1, self.num_rois, self.pool_size, self.pool_size, self.nb_channels))
# permute_dimensions is similar to transpose
final_output = keras.backend.permute_dimensions(final_output, (0, 1, 2, 3, 4))
# Return final output
return final_output
def get_config(self):
config = {'pool_size': self.pool_size, 'num_rois': self.num_rois}
base_config = super(RoiPoolingConv, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
# Create a rpn layer
def rpn_layer(base_layers, num_anchors):
x = keras.layers.Conv2D(512, (3, 3), padding='same', activation='relu', kernel_initializer='normal', name='rpn_conv1')(base_layers)
x_class = keras.layers.Conv2D(num_anchors, (1, 1), activation='sigmoid', kernel_initializer='uniform', name='rpn_out_class')(x)
x_regr = keras.layers.Conv2D(num_anchors * 4, (1, 1), activation='linear', kernel_initializer='zero', name='rpn_out_regress')(x)
return [x_class, x_regr, base_layers]
# Create a classifier layer
def classifier_layer(base_layers, input_rois, num_rois, nb_classes = 4):
input_shape = (num_rois,7,7,512)
pooling_regions = 7
# out_roi_pool.shape = (1, num_rois, channels, pool_size, pool_size)
# num_rois (4) 7x7 roi pooling
out_roi_pool = RoiPoolingConv(pooling_regions, num_rois)([base_layers, input_rois])
# Flatten the convlutional layer and connected to 2 FC and 2 dropout
out = keras.layers.TimeDistributed(keras.layers.Flatten(name='flatten'))(out_roi_pool)
out = keras.layers.TimeDistributed(keras.layers.Dense(4096, activation='relu', name='fc1'))(out)
out = keras.layers.TimeDistributed(keras.layers.Dropout(0.5))(out)
out = keras.layers.TimeDistributed(keras.layers.Dense(4096, activation='relu', name='fc2'))(out)
out = keras.layers.TimeDistributed(keras.layers.Dropout(0.5))(out)
# There are two output layer
# out_class: softmax acivation function for classify the class name of the object
# out_regr: linear activation function for bboxes coordinates regression
out_class = keras.layers.TimeDistributed(keras.layers.Dense(nb_classes, activation='softmax', kernel_initializer='zero'), name='dense_class_{}'.format(nb_classes))(out)
# note: no regression target for bg class
out_regr = keras.layers.TimeDistributed(keras.layers.Dense(4 * (nb_classes-1), activation='linear', kernel_initializer='zero'), name='dense_regress_{}'.format(nb_classes))(out)
return [out_class, out_regr]
# Apply regression layer to all anchors in one feature map
def apply_regr_np(X, T):
try:
x = X[0, :, :]
y = X[1, :, :]
w = X[2, :, :]
h = X[3, :, :]
tx = T[0, :, :]
ty = T[1, :, :]
tw = T[2, :, :]
th = T[3, :, :]
cx = x + w/2.
cy = y + h/2.
cx1 = tx * w + cx
cy1 = ty * h + cy
w1 = np.exp(tw.astype(np.float64)) * w
h1 = np.exp(th.astype(np.float64)) * h
x1 = cx1 - w1/2.
y1 = cy1 - h1/2.
x1 = np.round(x1)
y1 = np.round(y1)
w1 = np.round(w1)
h1 = np.round(h1)
return np.stack([x1, y1, w1, h1])
except Exception as e:
print(e)
return X
# Apply regression to x, y, w and h
def apply_regr(x, y, w, h, tx, ty, tw, th):
try:
cx = x + w/2.
cy = y + h/2.
cx1 = tx * w + cx
cy1 = ty * h + cy
w1 = math.exp(tw) * w
h1 = math.exp(th) * h
x1 = cx1 - w1/2.
y1 = cy1 - h1/2.
x1 = int(round(x1))
y1 = int(round(y1))
w1 = int(round(w1))
h1 = int(round(h1))
return x1, y1, w1, h1
except ValueError:
return x, y, w, h
except OverflowError:
return x, y, w, h
except Exception as e:
print(e)
return x, y, w, h
# Convert rpn layer to roi bboxes
def rpn_to_roi(rpn_layer, regr_layer, config, dim_ordering, use_regr=True, max_boxes=300,overlap_thresh=0.9):
# Make sure that there is configurations
if config == None:
config = common.Config()
# Create regression layer
regr_layer = regr_layer / config.std_scaling
anchor_sizes = config.anchor_box_scales # (3 in here)
anchor_ratios = config.anchor_box_ratios # (3 in here)
assert rpn_layer.shape[0] == 1
(rows, cols) = rpn_layer.shape[1:3]
curr_layer = 0
# A.shape = (4, feature_map.height, feature_map.width, num_anchors)
# Might be (4, 18, 25, 18) if resized image is 400 width and 300
# A is the coordinates for 9 anchors for every point in the feature map
# => all 18x25x9=4050 anchors cooridnates
A = np.zeros((4, rpn_layer.shape[1], rpn_layer.shape[2], rpn_layer.shape[3]))
for anchor_size in anchor_sizes:
for anchor_ratio in anchor_ratios:
# anchor_x = (128 * 1) / 16 = 8 => width of current anchor
# anchor_y = (128 * 2) / 16 = 16 => height of current anchor
anchor_x = (anchor_size * anchor_ratio[0])/config.rpn_stride
anchor_y = (anchor_size * anchor_ratio[1])/config.rpn_stride
# curr_layer: 0~8 (9 anchors)
# the Kth anchor of all position in the feature map (9th in total)
regr = regr_layer[0, :, :, 4 * curr_layer:4 * curr_layer + 4] # shape => (18, 25, 4)
regr = np.transpose(regr, (2, 0, 1)) # shape => (4, 18, 25)
# Create 18x25 mesh grid
# For every point in x, there are all the y points and vice versa
# X.shape = (18, 25)
# Y.shape = (18, 25)
X, Y = np.meshgrid(np.arange(cols),np. arange(rows))
# Calculate anchor position and size for each feature map point
A[0, :, :, curr_layer] = X - anchor_x/2 # Top left x coordinate
A[1, :, :, curr_layer] = Y - anchor_y/2 # Top left y coordinate
A[2, :, :, curr_layer] = anchor_x # width of current anchor
A[3, :, :, curr_layer] = anchor_y # height of current anchor
# Apply regression to x, y, w and h if there is rpn regression layer
if use_regr:
A[:, :, :, curr_layer] = apply_regr_np(A[:, :, :, curr_layer], regr)
# Avoid width and height exceeding 1
A[2, :, :, curr_layer] = np.maximum(1, A[2, :, :, curr_layer])
A[3, :, :, curr_layer] = np.maximum(1, A[3, :, :, curr_layer])
# Convert (x, y , w, h) to (x1, y1, x2, y2)
# x1, y1 is top left coordinate
# x2, y2 is bottom right coordinate
A[2, :, :, curr_layer] += A[0, :, :, curr_layer]
A[3, :, :, curr_layer] += A[1, :, :, curr_layer]
# Avoid bboxes drawn outside the feature map
A[0, :, :, curr_layer] = np.maximum(0, A[0, :, :, curr_layer])
A[1, :, :, curr_layer] = np.maximum(0, A[1, :, :, curr_layer])
A[2, :, :, curr_layer] = np.minimum(cols-1, A[2, :, :, curr_layer])
A[3, :, :, curr_layer] = np.minimum(rows-1, A[3, :, :, curr_layer])
curr_layer += 1
all_boxes = np.reshape(A.transpose((0, 3, 1, 2)), (4, -1)).transpose((1, 0)) # shape=(4050, 4)
all_probs = rpn_layer.transpose((0, 3, 1, 2)).reshape((-1)) # shape=(4050,)
x1 = all_boxes[:, 0]
y1 = all_boxes[:, 1]
x2 = all_boxes[:, 2]
y2 = all_boxes[:, 3]
# Find out the bboxes which is illegal and delete them from bboxes list
idxs = np.where((x1 - x2 >= 0) | (y1 - y2 >= 0))
all_boxes = np.delete(all_boxes, idxs, 0)
all_probs = np.delete(all_probs, idxs, 0)
# Apply non_max_suppression
# Only extract the bboxes. Don't need rpn probs in the later process
result = common.non_max_suppression_fast(all_boxes, all_probs, overlap_thresh=overlap_thresh, max_boxes=max_boxes)[0]
return resultModellbyggare
Denna modul används för att skapa träningsmodeller och inferensmodeller. En VGG-16-modell används som ryggradsmodell för bildklassificering, den valdes för att påskynda träningstiden.
# Import libraries
import keras
import annytab.frcnn.common as common
import annytab.frcnn.layers as layers
# Get a VGG-16 model
def get_vgg_16_model(input=None):
# Make sure that the input is okay
input_shape = (None, None, 3)
if input is None:
input = keras.layers.Input(shape=input_shape)
else:
if not keras.backend.is_keras_tensor(input):
input = keras.layers.Input(tensor=input, shape=input_shape)
# Set backbone axis
bn_axis = 3
# Block 1
x = keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv1')(input)
x = keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same', name='block1_conv2')(x)
x = keras.layers.MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv1')(x)
x = keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same', name='block2_conv2')(x)
x = keras.layers.MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv1')(x)
x = keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv2')(x)
x = keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same', name='block3_conv3')(x)
x = keras.layers.MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv1')(x)
x = keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv2')(x)
x = keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block4_conv3')(x)
x = keras.layers.MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv1')(x)
x = keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv2')(x)
x = keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same', name='block5_conv3')(x)
# x = keras.layers.MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
return x
# Get training models
def get_training_models(config=None, num_classes=3, weights_path=None):
# Make sure that there is configurations
if config == None:
config = common.Config()
# Calculate the number of anchors
num_anchors = len(config.anchor_box_scales) * len(config.anchor_box_ratios)
# Create input layers
img_input = keras.layers.Input(shape=(None, None, 3))
roi_input = keras.layers.Input(shape=(None, 4))
# Get a backbone model (VGG here, can be Resnet50, Inception, etc)
backbone = get_vgg_16_model(img_input)
# Create an rpn layer
rpn = layers.rpn_layer(backbone, num_anchors)
# Create a classifier
classifier = layers.classifier_layer(backbone, roi_input, config.num_rois, nb_classes=num_classes)
# Create models
rpn_model = keras.models.Model(img_input, rpn[:2])
classifier_model = keras.models.Model([img_input, roi_input], classifier)
total_model = keras.models.Model([img_input, roi_input], rpn[:2] + classifier)
# Load weights
if weights_path != None:
rpn_model.load_weights(weights_path, by_name=True)
classifier_model.load_weights(weights_path, by_name=True)
# Compile models
rpn_model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss=[common.rpn_loss_cls(num_anchors, config=config), common.rpn_loss_regr(num_anchors, config=config)])
classifier_model.compile(optimizer=keras.optimizers.Adam(lr=1e-5), loss=[common.class_loss_cls(config=config), common.class_loss_regr(num_classes-1, config=config)], metrics={'dense_class_{}'.format(num_classes): 'accuracy'})
total_model.compile(optimizer='sgd', loss='mae')
# Return models
return rpn_model, classifier_model, total_model
# Get inference models
def get_inference_models(config=None, num_classes=3, weights_path=None):
# Make sure that there is configurations
if config == None:
config = common.Config()
# Calculate the number of anchors
num_anchors = len(config.anchor_box_scales) * len(config.anchor_box_ratios)
# Create input layers
img_input = keras.layers.Input(shape=(None, None, 3))
roi_input = keras.layers.Input(shape=(config.num_rois, 4))
feature_map_input = keras.layers.Input(shape=(None, None, 512))
# Get a backbone model (VGG here, can be Resnet50, Inception, etc)
backbone = get_vgg_16_model(img_input)
# Create an rpn layer
rpn = layers.rpn_layer(backbone, num_anchors)
# Create a classifier
classifier = layers.classifier_layer(feature_map_input, roi_input, config.num_rois, nb_classes=num_classes)
# Create models
rpn_model = keras.models.Model(img_input, rpn)
classifier_only_model = keras.models.Model([feature_map_input, roi_input], classifier)
classifier_model = keras.models.Model([feature_map_input, roi_input], classifier)
# Load weights
rpn_model.load_weights(weights_path, by_name=True)
classifier_model.load_weights(weights_path, by_name=True)
# Compile models
rpn_model.compile(optimizer='sgd', loss='mse')
classifier_model.compile(optimizer='sgd', loss='mse')
# Return models
return rpn_model, classifier_model, classifier_only_modelFelsökning
Syftet med felsökning är att se till att annotationerna är korrekta, det är viktigt att kontrollera detta innan träningen påbörjas. Resultatet från en körning är en bild med uppritade rutor för varje objekt i bilden.
# Import libraries
import time
import cv2
import random
import numpy as np
import matplotlib.pyplot as plt
import annytab.frcnn.common as common
import tensorflow as tf
# The main entry point for this module
def main():
# Create configuration
config = common.Config()
config.annotations_file_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\train_annotations.csv'
config.img_base_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\'
config.use_horizontal_flips = True
config.use_vertical_flips = True
config.rot_90 = True
config.num_rois = 4
# Set the gpu to use
common.setup_gpu('cpu')
#common.setup_gpu(0)
#print('Tf with cuda:{0}'.format(tf.test.is_built_with_cuda()))
#print('Tf with cuda:{0}'.format(tf.test.is_gpu_available(cuda_only=False, min_cuda_compute_capability=None)))
# Get data
st = time.time()
images, classes, mappings = common.get_data(config)
print()
print('Spend {0:0.2f} mins to load the data'.format((time.time()-st)/60))
# Make sure that we have a bg class. A background region, this is usually for hard negative mining
if 'bg' not in classes:
classes['bg'] = 0
mappings['bg'] = len(mappings)
# Print class distribution
print('Training images per class:')
print(classes)
print('Num classes (including bg) = {}'.format(len(classes)))
print(mappings)
# Randomize images to get different each time
random.shuffle(images)
# Get a train generator
train_generator = common.get_anchor_gt(images, config, mode='test')
# Get the next element in the training set
X, Y, image_data, debug_img, debug_num_pos = next(train_generator)
# Output debug information
print('Original image: height={0} width={1}'.format(image_data['height'], image_data['width']))
print('Resized image: height={0} width={1} im_size={2}'.format(X.shape[1], X.shape[2], config.im_size))
print('Feature map size: height={0} width={1} rpn_stride={2}'.format(Y[0].shape[1], Y[0].shape[2], config.rpn_stride))
print(X.shape)
print(str(len(Y)) + ' includes y_rpn_cls and y_rpn_regr')
print('Shape of y_rpn_cls {0}'.format(Y[0].shape))
print('Shape of y_rpn_regr {0}'.format(Y[1].shape))
print(image_data)
print('Number of positive anchors for this image: {0}'.format(debug_num_pos))
if debug_num_pos==0:
gt_x1, gt_x2 = image_data['bboxes'][0]['x1']*(X.shape[2]/image_data['height']), image_data['bboxes'][0]['x2']*(X.shape[2]/image_data['height'])
gt_y1, gt_y2 = image_data['bboxes'][0]['y1']*(X.shape[1]/image_data['width']), image_data['bboxes'][0]['y2']*(X.shape[1]/image_data['width'])
gt_x1, gt_y1, gt_x2, gt_y2 = int(gt_x1), int(gt_y1), int(gt_x2), int(gt_y2)
img = debug_img.copy()
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
color = (0, 255, 0)
cv2.putText(img, 'gt bbox', (gt_x1, gt_y1+5), cv2.FONT_HERSHEY_PLAIN, 0.7, color, 1)
cv2.rectangle(img, (gt_x1, gt_y1), (gt_x2, gt_y2), color, 2)
cv2.circle(img, (int((gt_x1+gt_x2)/2), int((gt_y1+gt_y2)/2)), 3, color, -1)
# Display the image
plt.grid()
plt.imshow(img)
plt.show()
else:
cls = Y[0][0]
pos_cls = np.where(cls==1)
print(pos_cls)
regr = Y[1][0]
pos_regr = np.where(regr==1)
print(pos_regr)
print('y_rpn_cls for possible pos anchor: {0}'.format(cls[pos_cls[0][0],pos_cls[1][0],:]))
print('y_rpn_regr for positive anchor: {0}'.format(regr[pos_regr[0][0],pos_regr[1][0],:]))
gt_x1, gt_x2 = image_data['bboxes'][0]['x1']*(X.shape[2]/image_data['width']), image_data['bboxes'][0]['x2']*(X.shape[2]/image_data['width'])
gt_y1, gt_y2 = image_data['bboxes'][0]['y1']*(X.shape[1]/image_data['height']), image_data['bboxes'][0]['y2']*(X.shape[1]/image_data['height'])
gt_x1, gt_y1, gt_x2, gt_y2 = int(gt_x1), int(gt_y1), int(gt_x2), int(gt_y2)
img = debug_img.copy()
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
color = (0, 255, 0)
# cv2.putText(img, 'gt bbox', (gt_x1, gt_y1-5), cv2.FONT_HERSHEY_DUPLEX, 0.7, color, 1)
cv2.rectangle(img, (gt_x1, gt_y1), (gt_x2, gt_y2), color, 2)
cv2.circle(img, (int((gt_x1+gt_x2)/2), int((gt_y1+gt_y2)/2)), 3, color, -1)
# Add text
textLabel = 'gt bbox'
(retval,baseLine) = cv2.getTextSize(textLabel,cv2.FONT_HERSHEY_PLAIN,0.5,1)
textOrg = (gt_x1, gt_y1+5)
cv2.putText(img, textLabel, textOrg, cv2.FONT_HERSHEY_PLAIN, 0.5, (255, 255, 255), 1)
# Draw positive anchors according to the y_rpn_regr
for i in range(debug_num_pos):
color = (100+i*(155/4), 0, 100+i*(155/4))
idx = pos_regr[2][i*4]/4
anchor_size = config.anchor_box_scales[int(idx/3)]
anchor_ratio = config.anchor_box_ratios[2-int((idx+1)%3)]
center = (pos_regr[1][i*4]*config.rpn_stride, pos_regr[0][i*4]*config.rpn_stride)
print('Center position of positive anchor: ', center)
cv2.circle(img, center, 3, color, -1)
anc_w, anc_h = anchor_size*anchor_ratio[0], anchor_size*anchor_ratio[1]
cv2.rectangle(img, (center[0]-int(anc_w/2), center[1]-int(anc_h/2)), (center[0]+int(anc_w/2), center[1]+int(anc_h/2)), color, 2)
# Display the image
print('Green bboxes is ground-truth bbox. Others are positive anchors')
plt.figure(figsize=(8,8))
plt.grid()
plt.imshow(img)
plt.savefig('C:\\DATA\\Python-data\\open-images-v5\\frcnn\\plots\\debug.png')
#plt.show()
# Tell python to run main method
if __name__ == "__main__": main()Träning
Träningsmodeller skapas om ingen träning har utförts tidigare, vikter kan läsas in från en förtränad modell. Träningsmodeller laddas med sparade vikter om träning har genomförts tidigare, detta gör det möjligt för modellen att fortsätta sin träning (överföringsinlärning). Resultatet från en körning visas nedanför koden.
# Import libraries
import os
import time
import cv2
import keras
import numpy as np
import pandas as pd
import tensorflow as tf
import annytab.frcnn.common as common
import annytab.frcnn.model_builder as mb
import annytab.frcnn.layers as layers
# The main entry point for this module
def main():
# Create configuration
config = common.Config()
config.annotations_file_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\train_annotations.csv'
config.img_base_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\'
config.pretrained_model_path = 'C:\\DATA\\Python-data\\open-images-v5\\frcnn\\vgg16_weights_tf_dim_ordering_tf_kernels.h5'
config.model_path = 'C:\\DATA\\Python-data\\open-images-v5\\frcnn\\training_model.h5'
config.records_path = 'C:\\DATA\\Python-data\\open-images-v5\\frcnn\\records.csv'
config.use_horizontal_flips = True
config.use_vertical_flips = True
config.rot_90 = True
config.num_rois = 4
# Set the gpu to use
common.setup_gpu('cpu')
#common.setup_gpu(0)
# Get data
st = time.time()
images, classes, mappings = common.get_data(config)
print()
print('Spend {0:0.2f} mins to load the data'.format((time.time()-st)/60))
# Make sure that we have a bg class. A background region, this is usually for hard negative mining
if 'bg' not in classes:
classes['bg'] = 0
mappings['bg'] = len(mappings)
# Print class distribution
print('Training images per class:')
print(classes)
print('Number of classes (including bg) = {}'.format(len(classes)))
print(mappings)
# Get a train generator
train_generator = common.get_anchor_gt(images, config, mode='train')
# Get training models
if os.path.isfile(config.model_path):
# Get training models
model_rpn, model_classifier, model_all = mb.get_training_models(config, len(classes), weights_path=config.model_path)
# Load records
record_df = pd.read_csv(config.records_path)
r_mean_overlapping_bboxes = record_df['mean_overlapping_bboxes']
r_class_acc = record_df['class_acc']
r_loss_rpn_cls = record_df['loss_rpn_cls']
r_loss_rpn_regr = record_df['loss_rpn_regr']
r_loss_class_cls = record_df['loss_class_cls']
r_loss_class_regr = record_df['loss_class_regr']
r_curr_loss = record_df['curr_loss']
r_elapsed_time = record_df['elapsed_time']
r_mAP = record_df['mAP']
print('Already trained {0} batches'.format(len(record_df)))
else:
# Check if we can load weights from pretrained model or not
if os.path.isfile(config.pretrained_model_path):
model_rpn, model_classifier, model_all = mb.get_training_models(config, len(classes), weights_path=config.pretrained_model_path)
else:
model_rpn, model_classifier, model_all = mb.get_training_models(config, len(classes))
# Create a records dataframe
record_df = pd.DataFrame(columns=['mean_overlapping_bboxes', 'class_acc', 'loss_rpn_cls', 'loss_rpn_regr', 'loss_class_cls', 'loss_class_regr', 'curr_loss', 'elapsed_time', 'mAP'])
# Settings for training
total_epochs = len(record_df)
r_epochs = len(record_df)
steps = 240 # 240 images (epoch_length)
num_epochs = 1
iter_num = 0
total_epochs += num_epochs
losses = np.zeros((steps, 5))
rpn_accuracy_rpn_monitor = []
rpn_accuracy_for_epoch = []
if len(record_df)==0:
best_loss = np.Inf
else:
best_loss = np.min(r_curr_loss)
# Start training (one image on each iteration)
start_time = time.time()
# Loop epochs
for epoch_num in range(num_epochs):
# Create a progress bar
progbar = keras.utils.Progbar(steps)
# Print the current epoch
print('Epoch {}/{}'.format(r_epochs + 1, total_epochs))
r_epochs += 1
while True:
try:
if len(rpn_accuracy_rpn_monitor) == steps and config.verbose:
mean_overlapping_bboxes = float(sum(rpn_accuracy_rpn_monitor))/len(rpn_accuracy_rpn_monitor)
rpn_accuracy_rpn_monitor = []
if mean_overlapping_bboxes == 0:
print('RPN is not producing bounding boxes that overlap the ground truth boxes. Check RPN settings or keep training.')
# Get the next element from an generator
# Generate X (x_img) and label Y ([y_rpn_cls, y_rpn_regr])
X, Y, img_data, debug_img, debug_num_pos = next(train_generator)
# Train rpn model and get loss value [_, loss_rpn_cls, loss_rpn_regr]
loss_rpn = model_rpn.train_on_batch(X, Y)
# Get predicted rpn from rpn model [rpn_cls, rpn_regr]
P_rpn = model_rpn.predict_on_batch(X)
# R: bboxes (shape=(300,4))
# Convert rpn layer to roi bboxes
R = layers.rpn_to_roi(P_rpn[0], P_rpn[1], config, keras.backend.image_data_format(), use_regr=True, overlap_thresh=0.7, max_boxes=300)
# note: calc_iou converts from (x1,y1,x2,y2) to (x,y,w,h) format
# X2: bboxes that iou > config.classifier_min_overlap for all gt bboxes in 300 non_max_suppression bboxes
# Y1: one hot code for bboxes from above => x_roi (X)
# Y2: corresponding labels and corresponding gt bboxes
X2, Y1, Y2, IouS = common.calc_iou(R, img_data, config, mappings)
# If X2 is None means there are no matching bboxes
if X2 is None:
rpn_accuracy_rpn_monitor.append(0)
rpn_accuracy_for_epoch.append(0)
continue
# Find out the positive anchors and negative anchors
neg_samples = np.where(Y1[0, :, -1] == 1)
pos_samples = np.where(Y1[0, :, -1] == 0)
if len(neg_samples) > 0:
neg_samples = neg_samples[0]
else:
neg_samples = []
if len(pos_samples) > 0:
pos_samples = pos_samples[0]
else:
pos_samples = []
rpn_accuracy_rpn_monitor.append(len(pos_samples))
rpn_accuracy_for_epoch.append((len(pos_samples)))
if config.num_rois > 1:
# If number of positive anchors is larger than 4//2 = 2, randomly choose 2 pos samples
if len(pos_samples) < config.num_rois//2:
selected_pos_samples = pos_samples.tolist()
else:
selected_pos_samples = np.random.choice(pos_samples, config.num_rois//2, replace=False).tolist()
# Randomly choose (num_rois - num_pos) neg samples
try:
selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=False).tolist()
except:
selected_neg_samples = np.random.choice(neg_samples, config.num_rois - len(selected_pos_samples), replace=True).tolist()
# Save all the pos and neg samples in sel_samples
sel_samples = selected_pos_samples + selected_neg_samples
else:
# in the extreme case where num_rois = 1, we pick a random pos or neg sample
selected_pos_samples = pos_samples.tolist()
selected_neg_samples = neg_samples.tolist()
if np.random.randint(0, 2):
sel_samples = random.choice(neg_samples)
else:
sel_samples = random.choice(pos_samples)
# Train classifier
loss_class = model_classifier.train_on_batch([X, X2[:, sel_samples, :]], [Y1[:, sel_samples, :], Y2[:, sel_samples, :]])
losses[iter_num, 0] = loss_rpn[1]
losses[iter_num, 1] = loss_rpn[2]
losses[iter_num, 2] = loss_class[1]
losses[iter_num, 3] = loss_class[2]
losses[iter_num, 4] = loss_class[3]
iter_num += 1
# Update the progress bar
progbar.update(iter_num, [('rpn_cls', np.mean(losses[:iter_num, 0])), ('rpn_regr', np.mean(losses[:iter_num, 1])),
('final_cls', np.mean(losses[:iter_num, 2])), ('final_regr', np.mean(losses[:iter_num, 3]))])
# Free memory before each step
#tf.keras.backend.clear_session()
# Start the next step
if iter_num == steps:
loss_rpn_cls = np.mean(losses[:, 0])
loss_rpn_regr = np.mean(losses[:, 1])
loss_class_cls = np.mean(losses[:, 2])
loss_class_regr = np.mean(losses[:, 3])
class_acc = np.mean(losses[:, 4])
mean_overlapping_bboxes = float(sum(rpn_accuracy_for_epoch)) / len(rpn_accuracy_for_epoch)
rpn_accuracy_for_epoch = []
if config.verbose:
print('Mean number of bounding boxes from RPN overlapping ground truth boxes: {0}'.format(mean_overlapping_bboxes))
print('Classifier accuracy for bounding boxes from RPN: {0}'.format(class_acc))
print('Loss RPN classifier: {0}'.format(loss_rpn_cls))
print('Loss RPN regression: {0}'.format(loss_rpn_regr))
print('Loss Detector classifier: {0}'.format(loss_class_cls))
print('Loss Detector regression: {0}'.format(loss_class_regr))
print('Total loss: {0}'.format(loss_rpn_cls + loss_rpn_regr + loss_class_cls + loss_class_regr))
print('Elapsed time: {0}'.format(time.time() - start_time))
elapsed_time = (time.time()-start_time)/60
curr_loss = loss_rpn_cls + loss_rpn_regr + loss_class_cls + loss_class_regr
iter_num = 0
start_time = time.time()
# Save the model
if curr_loss < best_loss:
if config.verbose:
print('Total loss decreased from {0} to {1}, saving model.'.format(best_loss,curr_loss))
best_loss = curr_loss
#model_all.save_weights(config.model_path)
model_all.save(config.model_path)
# Create a new records row
new_row = {'mean_overlapping_bboxes':round(mean_overlapping_bboxes, 3),
'class_acc':round(class_acc, 3),
'loss_rpn_cls':round(loss_rpn_cls, 3),
'loss_rpn_regr':round(loss_rpn_regr, 3),
'loss_class_cls':round(loss_class_cls, 3),
'loss_class_regr':round(loss_class_regr, 3),
'curr_loss':round(curr_loss, 3),
'elapsed_time':round(elapsed_time, 3),
'mAP': 0}
# Append a new record row and save the file
record_df = record_df.append(new_row, ignore_index=True)
record_df.to_csv(config.records_path, index=0)
break
except Exception as e:
print('Exception: {}'.format(e))
continue
# Free memory after each epoch
#tf.keras.backend.clear_session()
print('Training complete, exiting.')
# Tell python to run main method
if __name__ == "__main__": main()Parsing annotation file
idx=450
Spend 0.05 mins to load the data
Training images per class:
{'Laptop': 165, 'Beer': 140, 'Goat': 145, 'bg': 0}
Number of classes (including bg) = 4
{'Laptop': 0, 'Beer': 1, 'Goat': 2, 'bg': 3}
Already trained 20 batches
Epoch 21/21
1/240 [..............................] - ETA: 1:03:56 - rpn_cls: 4.7960 - rpn_regr: 0.0395 - final_cls: 0.6163 - final_regr: 0.0289
2/240 [..............................] - ETA: 41:03 - rpn_cls: 4.5647 - rpn_regr: 0.0483 - final_cls: 0.5607 - final_regr: 0.0983
3/240 [..............................] - ETA: 33:39 - rpn_cls: 4.0262 - rpn_regr: 0.0673 - final_cls: 0.5503 - final_regr: 0.2006
4/240 [..............................] - ETA: 29:19 - rpn_cls: 3.5737 - rpn_regr: 0.0771 - final_cls: 0.5335 - final_regr: 0.2581
5/240 [..............................] - ETA: 27:29 - rpn_cls: 3.4570 - rpn_regr: 0.0868 - final_cls: 0.5348 - final_regr: 0.3002
6/240 [..............................] - ETA: 25:52 - rpn_cls: 3.2962 - rpn_regr: 0.0957 - final_cls: 0.5232 - final_regr: 0.3184
7/240 [..............................] - ETA: 24:50 - rpn_cls: 3.2421 - rpn_regr: 0.1264 - final_cls: 0.5137 - final_regr: 0.3230
8/240 [>.............................] - ETA: 23:48 - rpn_cls: 3.1559 - rpn_regr: 0.1496 - final_cls: 0.5022 - final_regr: 0.3277
9/240 [>.............................] - ETA: 23:00 - rpn_cls: 3.0965 - rpn_regr: 0.1687 - final_cls: 0.4918 - final_regr: 0.3349
10/240 [>.............................] - ETA: 22:29 - rpn_cls: 3.0849 - rpn_regr: 0.1911 - final_cls: 0.4800 - final_regr: 0.3368
11/240 [>.............................] - ETA: 22:05 - rpn_cls: 3.0511 - rpn_regr: 0.2091 - final_cls: 0.4674 - final_regr: 0.3353
12/240 [>.............................] - ETA: 21:53 - rpn_cls: 3.0447 - rpn_regr: 0.2244 - final_cls: 0.4614 - final_regr: 0.3363
13/240 [>.............................] - ETA: 21:27 - rpn_cls: 3.0216 - rpn_regr: 0.2360 - final_cls: 0.4546 - final_regr: 0.3387
14/240 [>.............................] - ETA: 21:03 - rpn_cls: 2.9878 - rpn_regr: 0.2441 - final_cls: 0.4488 - final_regr: 0.3412
15/240 [>.............................] - ETA: 20:39 - rpn_cls: 2.9472 - rpn_regr: 0.2509 - final_cls: 0.4469 - final_regr: 0.3427
16/240 [=>............................] - ETA: 20:17 - rpn_cls: 2.9265 - rpn_regr: 0.2572 - final_cls: 0.4436 - final_regr: 0.3427
17/240 [=>............................] - ETA: 19:55 - rpn_cls: 2.8991 - rpn_regr: 0.2616 - final_cls: 0.4420 - final_regr: 0.3424
18/240 [=>............................] - ETA: 19:45 - rpn_cls: 2.8681 - rpn_regr: 0.2670 - final_cls: 0.4394 - final_regr: 0.3410
19/240 [=>............................] - ETA: 19:30 - rpn_cls: 2.8514 - rpn_regr: 0.2710 - final_cls: 0.4363 - final_regr: 0.3390
20/240 [=>............................] - ETA: 19:11 - rpn_cls: 2.8300 - rpn_regr: 0.2751 - final_cls: 0.4355 - final_regr: 0.3373
21/240 [=>............................] - ETA: 19:01 - rpn_cls: 2.8089 - rpn_regr: 0.2795 - final_cls: 0.4358 - final_regr: 0.3358
22/240 [=>............................] - ETA: 18:50 - rpn_cls: 2.7848 - rpn_regr: 0.2831 - final_cls: 0.4370 - final_regr: 0.3353
23/240 [=>............................] - ETA: 18:43 - rpn_cls: 2.7666 - rpn_regr: 0.2865 - final_cls: 0.4383 - final_regr: 0.3348
24/240 [==>...........................] - ETA: 18:36 - rpn_cls: 2.7463 - rpn_regr: 0.2892 - final_cls: 0.4400 - final_regr: 0.3347
25/240 [==>...........................] - ETA: 18:30 - rpn_cls: 2.7250 - rpn_regr: 0.2912 - final_cls: 0.4411 - final_regr: 0.3346
26/240 [==>...........................] - ETA: 18:23 - rpn_cls: 2.7032 - rpn_regr: 0.2927 - final_cls: 0.4422 - final_regr: 0.3344
27/240 [==>...........................] - ETA: 18:13 - rpn_cls: 2.6800 - rpn_regr: 0.2940 - final_cls: 0.4433 - final_regr: 0.3344
28/240 [==>...........................] - ETA: 18:06 - rpn_cls: 2.6558 - rpn_regr: 0.2952 - final_cls: 0.4438 - final_regr: 0.3340
29/240 [==>...........................] - ETA: 17:58 - rpn_cls: 2.6339 - rpn_regr: 0.2969 - final_cls: 0.4455 - final_regr: 0.3335
30/240 [==>...........................] - ETA: 17:58 - rpn_cls: 2.6112 - rpn_regr: 0.2982 - final_cls: 0.4468 - final_regr: 0.3329
31/240 [==>...........................] - ETA: 17:50 - rpn_cls: 2.5880 - rpn_regr: 0.2993 - final_cls: 0.4478 - final_regr: 0.3326
32/240 [===>..........................] - ETA: 17:42 - rpn_cls: 2.5649 - rpn_regr: 0.3000 - final_cls: 0.4485 - final_regr: 0.3323
33/240 [===>..........................] - ETA: 17:35 - rpn_cls: 2.5415 - rpn_regr: 0.3008 - final_cls: 0.4490 - final_regr: 0.3320
34/240 [===>..........................] - ETA: 17:27 - rpn_cls: 2.5196 - rpn_regr: 0.3014 - final_cls: 0.4495 - final_regr: 0.3318
35/240 [===>..........................] - ETA: 17:21 - rpn_cls: 2.4976 - rpn_regr: 0.3018 - final_cls: 0.4501 - final_regr: 0.3316
36/240 [===>..........................] - ETA: 17:12 - rpn_cls: 2.4754 - rpn_regr: 0.3021 - final_cls: 0.4506 - final_regr: 0.3314
37/240 [===>..........................] - ETA: 17:06 - rpn_cls: 2.4532 - rpn_regr: 0.3022 - final_cls: 0.4509 - final_regr: 0.3311
38/240 [===>..........................] - ETA: 16:54 - rpn_cls: 2.4329 - rpn_regr: 0.3022 - final_cls: 0.4510 - final_regr: 0.3306
39/240 [===>..........................] - ETA: 16:46 - rpn_cls: 2.4126 - rpn_regr: 0.3021 - final_cls: 0.4511 - final_regr: 0.3300
40/240 [====>.........................] - ETA: 16:35 - rpn_cls: 2.3962 - rpn_regr: 0.3022 - final_cls: 0.4513 - final_regr: 0.3296
41/240 [====>.........................] - ETA: 16:27 - rpn_cls: 2.3796 - rpn_regr: 0.3023 - final_cls: 0.4519 - final_regr: 0.3292
42/240 [====>.........................] - ETA: 16:17 - rpn_cls: 2.3628 - rpn_regr: 0.3023 - final_cls: 0.4523 - final_regr: 0.3288
43/240 [====>.........................] - ETA: 16:09 - rpn_cls: 2.3463 - rpn_regr: 0.3021 - final_cls: 0.4528 - final_regr: 0.3285
44/240 [====>.........................] - ETA: 16:04 - rpn_cls: 2.3296 - rpn_regr: 0.3019 - final_cls: 0.4536 - final_regr: 0.3283
45/240 [====>.........................] - ETA: 15:57 - rpn_cls: 2.3136 - rpn_regr: 0.3017 - final_cls: 0.4546 - final_regr: 0.3282
46/240 [====>.........................] - ETA: 15:51 - rpn_cls: 2.2989 - rpn_regr: 0.3016 - final_cls: 0.4555 - final_regr: 0.3283
47/240 [====>.........................] - ETA: 15:45 - rpn_cls: 2.2841 - rpn_regr: 0.3015 - final_cls: 0.4565 - final_regr: 0.3285
48/240 [=====>........................] - ETA: 15:39 - rpn_cls: 2.2692 - rpn_regr: 0.3014 - final_cls: 0.4573 - final_regr: 0.3285
49/240 [=====>........................] - ETA: 15:32 - rpn_cls: 2.2569 - rpn_regr: 0.3012 - final_cls: 0.4588 - final_regr: 0.3287
50/240 [=====>........................] - ETA: 15:26 - rpn_cls: 2.2450 - rpn_regr: 0.3010 - final_cls: 0.4605 - final_regr: 0.3288
51/240 [=====>........................] - ETA: 15:20 - rpn_cls: 2.2341 - rpn_regr: 0.3009 - final_cls: 0.4619 - final_regr: 0.3289
52/240 [=====>........................] - ETA: 15:15 - rpn_cls: 2.2231 - rpn_regr: 0.3007 - final_cls: 0.4630 - final_regr: 0.3288
53/240 [=====>........................] - ETA: 15:10 - rpn_cls: 2.2128 - rpn_regr: 0.3004 - final_cls: 0.4644 - final_regr: 0.3288
54/240 [=====>........................] - ETA: 15:04 - rpn_cls: 2.2024 - rpn_regr: 0.3001 - final_cls: 0.4656 - final_regr: 0.3287
55/240 [=====>........................] - ETA: 14:59 - rpn_cls: 2.1919 - rpn_regr: 0.2998 - final_cls: 0.4666 - final_regr: 0.3286
56/240 [======>.......................] - ETA: 14:53 - rpn_cls: 2.1813 - rpn_regr: 0.2994 - final_cls: 0.4674 - final_regr: 0.3286
57/240 [======>.......................] - ETA: 14:48 - rpn_cls: 2.1705 - rpn_regr: 0.2990 - final_cls: 0.4683 - final_regr: 0.3286
58/240 [======>.......................] - ETA: 14:43 - rpn_cls: 2.1618 - rpn_regr: 0.2990 - final_cls: 0.4690 - final_regr: 0.3286
59/240 [======>.......................] - ETA: 14:38 - rpn_cls: 2.1546 - rpn_regr: 0.2990 - final_cls: 0.4696 - final_regr: 0.3285
60/240 [======>.......................] - ETA: 14:33 - rpn_cls: 2.1477 - rpn_regr: 0.2991 - final_cls: 0.4707 - final_regr: 0.3285
61/240 [======>.......................] - ETA: 14:28 - rpn_cls: 2.1420 - rpn_regr: 0.2991 - final_cls: 0.4716 - final_regr: 0.3284
62/240 [======>.......................] - ETA: 14:23 - rpn_cls: 2.1362 - rpn_regr: 0.2995 - final_cls: 0.4725 - final_regr: 0.3283
63/240 [======>.......................] - ETA: 14:17 - rpn_cls: 2.1304 - rpn_regr: 0.2997 - final_cls: 0.4732 - final_regr: 0.3284
64/240 [=======>......................] - ETA: 14:13 - rpn_cls: 2.1258 - rpn_regr: 0.3000 - final_cls: 0.4740 - final_regr: 0.3284
65/240 [=======>......................] - ETA: 14:08 - rpn_cls: 2.1217 - rpn_regr: 0.3002 - final_cls: 0.4747 - final_regr: 0.3285
66/240 [=======>......................] - ETA: 14:04 - rpn_cls: 2.1175 - rpn_regr: 0.3005 - final_cls: 0.4754 - final_regr: 0.3286
67/240 [=======>......................] - ETA: 13:59 - rpn_cls: 2.1142 - rpn_regr: 0.3007 - final_cls: 0.4760 - final_regr: 0.3287
68/240 [=======>......................] - ETA: 13:54 - rpn_cls: 2.1108 - rpn_regr: 0.3009 - final_cls: 0.4767 - final_regr: 0.3289
69/240 [=======>......................] - ETA: 13:48 - rpn_cls: 2.1070 - rpn_regr: 0.3010 - final_cls: 0.4774 - final_regr: 0.3291
70/240 [=======>......................] - ETA: 13:42 - rpn_cls: 2.1030 - rpn_regr: 0.3013 - final_cls: 0.4783 - final_regr: 0.3293
71/240 [=======>......................] - ETA: 13:37 - rpn_cls: 2.0990 - rpn_regr: 0.3015 - final_cls: 0.4791 - final_regr: 0.3295
72/240 [========>.....................] - ETA: 13:31 - rpn_cls: 2.0950 - rpn_regr: 0.3016 - final_cls: 0.4800 - final_regr: 0.3297
73/240 [========>.....................] - ETA: 13:24 - rpn_cls: 2.0907 - rpn_regr: 0.3017 - final_cls: 0.4809 - final_regr: 0.3299
74/240 [========>.....................] - ETA: 13:19 - rpn_cls: 2.0871 - rpn_regr: 0.3019 - final_cls: 0.4817 - final_regr: 0.3302
75/240 [========>.....................] - ETA: 13:12 - rpn_cls: 2.0833 - rpn_regr: 0.3020 - final_cls: 0.4825 - final_regr: 0.3305
76/240 [========>.....................] - ETA: 13:07 - rpn_cls: 2.0798 - rpn_regr: 0.3021 - final_cls: 0.4833 - final_regr: 0.3308
77/240 [========>.....................] - ETA: 13:03 - rpn_cls: 2.0760 - rpn_regr: 0.3021 - final_cls: 0.4842 - final_regr: 0.3311
78/240 [========>.....................] - ETA: 12:59 - rpn_cls: 2.0731 - rpn_regr: 0.3023 - final_cls: 0.4851 - final_regr: 0.3314
79/240 [========>.....................] - ETA: 12:55 - rpn_cls: 2.0701 - rpn_regr: 0.3025 - final_cls: 0.4861 - final_regr: 0.3317
80/240 [=========>....................] - ETA: 12:49 - rpn_cls: 2.0669 - rpn_regr: 0.3027 - final_cls: 0.4869 - final_regr: 0.3319
81/240 [=========>....................] - ETA: 12:44 - rpn_cls: 2.0635 - rpn_regr: 0.3028 - final_cls: 0.4878 - final_regr: 0.3321
82/240 [=========>....................] - ETA: 12:39 - rpn_cls: 2.0599 - rpn_regr: 0.3029 - final_cls: 0.4886 - final_regr: 0.3323
83/240 [=========>....................] - ETA: 12:34 - rpn_cls: 2.0562 - rpn_regr: 0.3030 - final_cls: 0.4895 - final_regr: 0.3324
84/240 [=========>....................] - ETA: 12:29 - rpn_cls: 2.0531 - rpn_regr: 0.3030 - final_cls: 0.4904 - final_regr: 0.3326
85/240 [=========>....................] - ETA: 12:24 - rpn_cls: 2.0508 - rpn_regr: 0.3030 - final_cls: 0.4913 - final_regr: 0.3327
86/240 [=========>....................] - ETA: 12:18 - rpn_cls: 2.0483 - rpn_regr: 0.3031 - final_cls: 0.4922 - final_regr: 0.3328
87/240 [=========>....................] - ETA: 12:13 - rpn_cls: 2.0457 - rpn_regr: 0.3031 - final_cls: 0.4930 - final_regr: 0.3330
88/240 [==========>...................] - ETA: 12:09 - rpn_cls: 2.0433 - rpn_regr: 0.3032 - final_cls: 0.4938 - final_regr: 0.3331
89/240 [==========>...................] - ETA: 12:05 - rpn_cls: 2.0416 - rpn_regr: 0.3033 - final_cls: 0.4947 - final_regr: 0.3333
90/240 [==========>...................] - ETA: 12:01 - rpn_cls: 2.0398 - rpn_regr: 0.3034 - final_cls: 0.4955 - final_regr: 0.3335
91/240 [==========>...................] - ETA: 11:55 - rpn_cls: 2.0380 - rpn_regr: 0.3035 - final_cls: 0.4964 - final_regr: 0.3337
92/240 [==========>...................] - ETA: 11:51 - rpn_cls: 2.0361 - rpn_regr: 0.3035 - final_cls: 0.4972 - final_regr: 0.3338
93/240 [==========>...................] - ETA: 11:46 - rpn_cls: 2.0341 - rpn_regr: 0.3035 - final_cls: 0.4979 - final_regr: 0.3340
94/240 [==========>...................] - ETA: 11:40 - rpn_cls: 2.0328 - rpn_regr: 0.3036 - final_cls: 0.4986 - final_regr: 0.3341
95/240 [==========>...................] - ETA: 11:35 - rpn_cls: 2.0314 - rpn_regr: 0.3037 - final_cls: 0.4993 - final_regr: 0.3342
96/240 [===========>..................] - ETA: 11:29 - rpn_cls: 2.0299 - rpn_regr: 0.3038 - final_cls: 0.5000 - final_regr: 0.3342
97/240 [===========>..................] - ETA: 11:24 - rpn_cls: 2.0283 - rpn_regr: 0.3038 - final_cls: 0.5006 - final_regr: 0.3343
98/240 [===========>..................] - ETA: 11:19 - rpn_cls: 2.0267 - rpn_regr: 0.3039 - final_cls: 0.5013 - final_regr: 0.3344
99/240 [===========>..................] - ETA: 11:14 - rpn_cls: 2.0252 - rpn_regr: 0.3040 - final_cls: 0.5018 - final_regr: 0.3344
100/240 [===========>..................] - ETA: 11:09 - rpn_cls: 2.0235 - rpn_regr: 0.3040 - final_cls: 0.5025 - final_regr: 0.3345
101/240 [===========>..................] - ETA: 11:05 - rpn_cls: 2.0218 - rpn_regr: 0.3041 - final_cls: 0.5031 - final_regr: 0.3345
102/240 [===========>..................] - ETA: 11:00 - rpn_cls: 2.0200 - rpn_regr: 0.3041 - final_cls: 0.5037 - final_regr: 0.3346
103/240 [===========>..................] - ETA: 10:55 - rpn_cls: 2.0181 - rpn_regr: 0.3041 - final_cls: 0.5043 - final_regr: 0.3346
104/240 [============>.................] - ETA: 10:50 - rpn_cls: 2.0161 - rpn_regr: 0.3041 - final_cls: 0.5048 - final_regr: 0.3345
105/240 [============>.................] - ETA: 10:45 - rpn_cls: 2.0139 - rpn_regr: 0.3041 - final_cls: 0.5054 - final_regr: 0.3345
106/240 [============>.................] - ETA: 10:40 - rpn_cls: 2.0119 - rpn_regr: 0.3040 - final_cls: 0.5059 - final_regr: 0.3345
107/240 [============>.................] - ETA: 10:35 - rpn_cls: 2.0098 - rpn_regr: 0.3039 - final_cls: 0.5065 - final_regr: 0.3344
108/240 [============>.................] - ETA: 10:30 - rpn_cls: 2.0076 - rpn_regr: 0.3039 - final_cls: 0.5070 - final_regr: 0.3345
109/240 [============>.................] - ETA: 10:26 - rpn_cls: 2.0058 - rpn_regr: 0.3039 - final_cls: 0.5075 - final_regr: 0.3345
110/240 [============>.................] - ETA: 10:21 - rpn_cls: 2.0040 - rpn_regr: 0.3038 - final_cls: 0.5081 - final_regr: 0.3346
111/240 [============>.................] - ETA: 10:17 - rpn_cls: 2.0022 - rpn_regr: 0.3038 - final_cls: 0.5087 - final_regr: 0.3346
112/240 [=============>................] - ETA: 10:11 - rpn_cls: 2.0006 - rpn_regr: 0.3038 - final_cls: 0.5092 - final_regr: 0.3346
113/240 [=============>................] - ETA: 10:06 - rpn_cls: 1.9988 - rpn_regr: 0.3038 - final_cls: 0.5097 - final_regr: 0.3347
114/240 [=============>................] - ETA: 10:02 - rpn_cls: 1.9970 - rpn_regr: 0.3037 - final_cls: 0.5102 - final_regr: 0.3347
115/240 [=============>................] - ETA: 9:58 - rpn_cls: 1.9954 - rpn_regr: 0.3037 - final_cls: 0.5106 - final_regr: 0.3347
116/240 [=============>................] - ETA: 9:53 - rpn_cls: 1.9938 - rpn_regr: 0.3036 - final_cls: 0.5110 - final_regr: 0.3348
117/240 [=============>................] - ETA: 9:48 - rpn_cls: 1.9921 - rpn_regr: 0.3036 - final_cls: 0.5113 - final_regr: 0.3348
118/240 [=============>................] - ETA: 9:43 - rpn_cls: 1.9903 - rpn_regr: 0.3035 - final_cls: 0.5117 - final_regr: 0.3348
119/240 [=============>................] - ETA: 9:37 - rpn_cls: 1.9885 - rpn_regr: 0.3034 - final_cls: 0.5120 - final_regr: 0.3348
120/240 [==============>...............] - ETA: 9:32 - rpn_cls: 1.9869 - rpn_regr: 0.3033 - final_cls: 0.5124 - final_regr: 0.3348
121/240 [==============>...............] - ETA: 9:27 - rpn_cls: 1.9853 - rpn_regr: 0.3033 - final_cls: 0.5127 - final_regr: 0.3348
122/240 [==============>...............] - ETA: 9:22 - rpn_cls: 1.9837 - rpn_regr: 0.3032 - final_cls: 0.5131 - final_regr: 0.3348
123/240 [==============>...............] - ETA: 9:16 - rpn_cls: 1.9821 - rpn_regr: 0.3031 - final_cls: 0.5134 - final_regr: 0.3348
124/240 [==============>...............] - ETA: 9:11 - rpn_cls: 1.9804 - rpn_regr: 0.3030 - final_cls: 0.5137 - final_regr: 0.3348
125/240 [==============>...............] - ETA: 9:06 - rpn_cls: 1.9787 - rpn_regr: 0.3029 - final_cls: 0.5140 - final_regr: 0.3348
126/240 [==============>...............] - ETA: 9:01 - rpn_cls: 1.9771 - rpn_regr: 0.3028 - final_cls: 0.5143 - final_regr: 0.3347
127/240 [==============>...............] - ETA: 8:55 - rpn_cls: 1.9755 - rpn_regr: 0.3026 - final_cls: 0.5145 - final_regr: 0.3348
128/240 [===============>..............] - ETA: 8:50 - rpn_cls: 1.9738 - rpn_regr: 0.3025 - final_cls: 0.5148 - final_regr: 0.3348
129/240 [===============>..............] - ETA: 8:45 - rpn_cls: 1.9721 - rpn_regr: 0.3024 - final_cls: 0.5150 - final_regr: 0.3348
130/240 [===============>..............] - ETA: 8:40 - rpn_cls: 1.9703 - rpn_regr: 0.3022 - final_cls: 0.5153 - final_regr: 0.3348
131/240 [===============>..............] - ETA: 8:35 - rpn_cls: 1.9684 - rpn_regr: 0.3021 - final_cls: 0.5154 - final_regr: 0.3347
132/240 [===============>..............] - ETA: 8:30 - rpn_cls: 1.9664 - rpn_regr: 0.3019 - final_cls: 0.5157 - final_regr: 0.3347
133/240 [===============>..............] - ETA: 8:25 - rpn_cls: 1.9648 - rpn_regr: 0.3018 - final_cls: 0.5159 - final_regr: 0.3347
134/240 [===============>..............] - ETA: 8:20 - rpn_cls: 1.9630 - rpn_regr: 0.3017 - final_cls: 0.5161 - final_regr: 0.3347
135/240 [===============>..............] - ETA: 8:15 - rpn_cls: 1.9612 - rpn_regr: 0.3016 - final_cls: 0.5164 - final_regr: 0.3347
136/240 [================>.............] - ETA: 8:10 - rpn_cls: 1.9594 - rpn_regr: 0.3014 - final_cls: 0.5167 - final_regr: 0.3347
137/240 [================>.............] - ETA: 8:05 - rpn_cls: 1.9577 - rpn_regr: 0.3013 - final_cls: 0.5169 - final_regr: 0.3346
138/240 [================>.............] - ETA: 8:00 - rpn_cls: 1.9559 - rpn_regr: 0.3012 - final_cls: 0.5172 - final_regr: 0.3346
139/240 [================>.............] - ETA: 7:54 - rpn_cls: 1.9542 - rpn_regr: 0.3010 - final_cls: 0.5174 - final_regr: 0.3346
140/240 [================>.............] - ETA: 7:49 - rpn_cls: 1.9524 - rpn_regr: 0.3009 - final_cls: 0.5177 - final_regr: 0.3346
141/240 [================>.............] - ETA: 7:45 - rpn_cls: 1.9507 - rpn_regr: 0.3007 - final_cls: 0.5179 - final_regr: 0.3345
142/240 [================>.............] - ETA: 7:39 - rpn_cls: 1.9490 - rpn_regr: 0.3006 - final_cls: 0.5181 - final_regr: 0.3345
143/240 [================>.............] - ETA: 7:35 - rpn_cls: 1.9472 - rpn_regr: 0.3004 - final_cls: 0.5184 - final_regr: 0.3345
144/240 [=================>............] - ETA: 7:30 - rpn_cls: 1.9454 - rpn_regr: 0.3002 - final_cls: 0.5187 - final_regr: 0.3344
145/240 [=================>............] - ETA: 7:25 - rpn_cls: 1.9436 - rpn_regr: 0.3001 - final_cls: 0.5189 - final_regr: 0.3344
146/240 [=================>............] - ETA: 7:20 - rpn_cls: 1.9418 - rpn_regr: 0.2999 - final_cls: 0.5192 - final_regr: 0.3343
147/240 [=================>............] - ETA: 7:15 - rpn_cls: 1.9401 - rpn_regr: 0.2997 - final_cls: 0.5194 - final_regr: 0.3343
148/240 [=================>............] - ETA: 7:10 - rpn_cls: 1.9385 - rpn_regr: 0.2996 - final_cls: 0.5196 - final_regr: 0.3343
149/240 [=================>............] - ETA: 7:06 - rpn_cls: 1.9367 - rpn_regr: 0.2994 - final_cls: 0.5198 - final_regr: 0.3342
150/240 [=================>............] - ETA: 7:01 - rpn_cls: 1.9350 - rpn_regr: 0.2992 - final_cls: 0.5200 - final_regr: 0.3342
151/240 [=================>............] - ETA: 6:56 - rpn_cls: 1.9333 - rpn_regr: 0.2991 - final_cls: 0.5202 - final_regr: 0.3341
152/240 [==================>...........] - ETA: 6:51 - rpn_cls: 1.9315 - rpn_regr: 0.2989 - final_cls: 0.5203 - final_regr: 0.3341
153/240 [==================>...........] - ETA: 6:46 - rpn_cls: 1.9297 - rpn_regr: 0.2987 - final_cls: 0.5205 - final_regr: 0.3340
154/240 [==================>...........] - ETA: 6:41 - rpn_cls: 1.9279 - rpn_regr: 0.2985 - final_cls: 0.5206 - final_regr: 0.3339
155/240 [==================>...........] - ETA: 6:36 - rpn_cls: 1.9262 - rpn_regr: 0.2983 - final_cls: 0.5208 - final_regr: 0.3339
156/240 [==================>...........] - ETA: 6:31 - rpn_cls: 1.9246 - rpn_regr: 0.2981 - final_cls: 0.5209 - final_regr: 0.3338
157/240 [==================>...........] - ETA: 6:26 - rpn_cls: 1.9230 - rpn_regr: 0.2979 - final_cls: 0.5211 - final_regr: 0.3337
158/240 [==================>...........] - ETA: 6:22 - rpn_cls: 1.9213 - rpn_regr: 0.2977 - final_cls: 0.5212 - final_regr: 0.3336
159/240 [==================>...........] - ETA: 6:16 - rpn_cls: 1.9196 - rpn_regr: 0.2975 - final_cls: 0.5213 - final_regr: 0.3335
160/240 [===================>..........] - ETA: 6:11 - rpn_cls: 1.9179 - rpn_regr: 0.2973 - final_cls: 0.5214 - final_regr: 0.3334
161/240 [===================>..........] - ETA: 6:07 - rpn_cls: 1.9161 - rpn_regr: 0.2971 - final_cls: 0.5214 - final_regr: 0.3333
162/240 [===================>..........] - ETA: 6:01 - rpn_cls: 1.9143 - rpn_regr: 0.2969 - final_cls: 0.5215 - final_regr: 0.3332
163/240 [===================>..........] - ETA: 5:57 - rpn_cls: 1.9129 - rpn_regr: 0.2968 - final_cls: 0.5215 - final_regr: 0.3331
164/240 [===================>..........] - ETA: 5:52 - rpn_cls: 1.9115 - rpn_regr: 0.2966 - final_cls: 0.5216 - final_regr: 0.3330
165/240 [===================>..........] - ETA: 5:47 - rpn_cls: 1.9101 - rpn_regr: 0.2964 - final_cls: 0.5216 - final_regr: 0.3329
166/240 [===================>..........] - ETA: 5:42 - rpn_cls: 1.9088 - rpn_regr: 0.2962 - final_cls: 0.5216 - final_regr: 0.3328
167/240 [===================>..........] - ETA: 5:37 - rpn_cls: 1.9076 - rpn_regr: 0.2960 - final_cls: 0.5217 - final_regr: 0.3327
168/240 [====================>.........] - ETA: 5:32 - rpn_cls: 1.9064 - rpn_regr: 0.2958 - final_cls: 0.5217 - final_regr: 0.3326
169/240 [====================>.........] - ETA: 5:27 - rpn_cls: 1.9052 - rpn_regr: 0.2956 - final_cls: 0.5217 - final_regr: 0.3325
170/240 [====================>.........] - ETA: 5:22 - rpn_cls: 1.9039 - rpn_regr: 0.2954 - final_cls: 0.5217 - final_regr: 0.3324
171/240 [====================>.........] - ETA: 5:18 - rpn_cls: 1.9027 - rpn_regr: 0.2952 - final_cls: 0.5217 - final_regr: 0.3323
172/240 [====================>.........] - ETA: 5:13 - rpn_cls: 1.9015 - rpn_regr: 0.2951 - final_cls: 0.5217 - final_regr: 0.3322
173/240 [====================>.........] - ETA: 5:08 - rpn_cls: 1.9003 - rpn_regr: 0.2949 - final_cls: 0.5218 - final_regr: 0.3321
174/240 [====================>.........] - ETA: 5:04 - rpn_cls: 1.8991 - rpn_regr: 0.2947 - final_cls: 0.5218 - final_regr: 0.3320
175/240 [====================>.........] - ETA: 4:59 - rpn_cls: 1.8979 - rpn_regr: 0.2945 - final_cls: 0.5218 - final_regr: 0.3319
176/240 [=====================>........] - ETA: 4:54 - rpn_cls: 1.8967 - rpn_regr: 0.2943 - final_cls: 0.5218 - final_regr: 0.3318
177/240 [=====================>........] - ETA: 4:49 - rpn_cls: 1.8955 - rpn_regr: 0.2941 - final_cls: 0.5218 - final_regr: 0.3317
178/240 [=====================>........] - ETA: 4:45 - rpn_cls: 1.8943 - rpn_regr: 0.2939 - final_cls: 0.5219 - final_regr: 0.3316
179/240 [=====================>........] - ETA: 4:40 - rpn_cls: 1.8930 - rpn_regr: 0.2937 - final_cls: 0.5219 - final_regr: 0.3316
180/240 [=====================>........] - ETA: 4:35 - rpn_cls: 1.8917 - rpn_regr: 0.2935 - final_cls: 0.5219 - final_regr: 0.3315
181/240 [=====================>........] - ETA: 4:31 - rpn_cls: 1.8904 - rpn_regr: 0.2934 - final_cls: 0.5219 - final_regr: 0.3314
182/240 [=====================>........] - ETA: 4:26 - rpn_cls: 1.8890 - rpn_regr: 0.2932 - final_cls: 0.5220 - final_regr: 0.3313
183/240 [=====================>........] - ETA: 4:21 - rpn_cls: 1.8876 - rpn_regr: 0.2930 - final_cls: 0.5220 - final_regr: 0.3313
184/240 [======================>.......] - ETA: 4:16 - rpn_cls: 1.8863 - rpn_regr: 0.2929 - final_cls: 0.5220 - final_regr: 0.3312
185/240 [======================>.......] - ETA: 4:12 - rpn_cls: 1.8850 - rpn_regr: 0.2927 - final_cls: 0.5221 - final_regr: 0.3312
186/240 [======================>.......] - ETA: 4:07 - rpn_cls: 1.8837 - rpn_regr: 0.2925 - final_cls: 0.5221 - final_regr: 0.3311
187/240 [======================>.......] - ETA: 4:03 - rpn_cls: 1.8824 - rpn_regr: 0.2924 - final_cls: 0.5222 - final_regr: 0.3311
188/240 [======================>.......] - ETA: 3:58 - rpn_cls: 1.8811 - rpn_regr: 0.2922 - final_cls: 0.5222 - final_regr: 0.3310
189/240 [======================>.......] - ETA: 3:53 - rpn_cls: 1.8797 - rpn_regr: 0.2920 - final_cls: 0.5222 - final_regr: 0.3309
190/240 [======================>.......] - ETA: 3:49 - rpn_cls: 1.8783 - rpn_regr: 0.2918 - final_cls: 0.5223 - final_regr: 0.3309
191/240 [======================>.......] - ETA: 3:44 - rpn_cls: 1.8770 - rpn_regr: 0.2917 - final_cls: 0.5223 - final_regr: 0.3308
192/240 [=======================>......] - ETA: 3:39 - rpn_cls: 1.8756 - rpn_regr: 0.2915 - final_cls: 0.5223 - final_regr: 0.3307
193/240 [=======================>......] - ETA: 3:35 - rpn_cls: 1.8742 - rpn_regr: 0.2913 - final_cls: 0.5223 - final_regr: 0.3307
194/240 [=======================>......] - ETA: 3:30 - rpn_cls: 1.8728 - rpn_regr: 0.2911 - final_cls: 0.5224 - final_regr: 0.3306
195/240 [=======================>......] - ETA: 3:25 - rpn_cls: 1.8715 - rpn_regr: 0.2910 - final_cls: 0.5224 - final_regr: 0.3306
196/240 [=======================>......] - ETA: 3:21 - rpn_cls: 1.8702 - rpn_regr: 0.2908 - final_cls: 0.5224 - final_regr: 0.3305
197/240 [=======================>......] - ETA: 3:16 - rpn_cls: 1.8690 - rpn_regr: 0.2906 - final_cls: 0.5224 - final_regr: 0.3305
198/240 [=======================>......] - ETA: 3:11 - rpn_cls: 1.8678 - rpn_regr: 0.2904 - final_cls: 0.5224 - final_regr: 0.3305
199/240 [=======================>......] - ETA: 3:06 - rpn_cls: 1.8666 - rpn_regr: 0.2902 - final_cls: 0.5225 - final_regr: 0.3304
200/240 [========================>.....] - ETA: 3:02 - rpn_cls: 1.8654 - rpn_regr: 0.2901 - final_cls: 0.5225 - final_regr: 0.3304
201/240 [========================>.....] - ETA: 2:57 - rpn_cls: 1.8641 - rpn_regr: 0.2899 - final_cls: 0.5225 - final_regr: 0.3303
202/240 [========================>.....] - ETA: 2:52 - rpn_cls: 1.8629 - rpn_regr: 0.2897 - final_cls: 0.5225 - final_regr: 0.3303
203/240 [========================>.....] - ETA: 2:48 - rpn_cls: 1.8616 - rpn_regr: 0.2895 - final_cls: 0.5225 - final_regr: 0.3303
204/240 [========================>.....] - ETA: 2:43 - rpn_cls: 1.8603 - rpn_regr: 0.2894 - final_cls: 0.5225 - final_regr: 0.3302
205/240 [========================>.....] - ETA: 2:39 - rpn_cls: 1.8589 - rpn_regr: 0.2892 - final_cls: 0.5225 - final_regr: 0.3302
206/240 [========================>.....] - ETA: 2:34 - rpn_cls: 1.8577 - rpn_regr: 0.2890 - final_cls: 0.5225 - final_regr: 0.3301
207/240 [========================>.....] - ETA: 2:29 - rpn_cls: 1.8564 - rpn_regr: 0.2888 - final_cls: 0.5225 - final_regr: 0.3301
208/240 [=========================>....] - ETA: 2:25 - rpn_cls: 1.8552 - rpn_regr: 0.2886 - final_cls: 0.5225 - final_regr: 0.3301
209/240 [=========================>....] - ETA: 2:20 - rpn_cls: 1.8540 - rpn_regr: 0.2885 - final_cls: 0.5225 - final_regr: 0.3300
210/240 [=========================>....] - ETA: 2:16 - rpn_cls: 1.8527 - rpn_regr: 0.2883 - final_cls: 0.5225 - final_regr: 0.3300
211/240 [=========================>....] - ETA: 2:11 - rpn_cls: 1.8515 - rpn_regr: 0.2881 - final_cls: 0.5225 - final_regr: 0.3300
212/240 [=========================>....] - ETA: 2:06 - rpn_cls: 1.8502 - rpn_regr: 0.2879 - final_cls: 0.5225 - final_regr: 0.3300
213/240 [=========================>....] - ETA: 2:02 - rpn_cls: 1.8489 - rpn_regr: 0.2878 - final_cls: 0.5225 - final_regr: 0.3300
214/240 [=========================>....] - ETA: 1:57 - rpn_cls: 1.8476 - rpn_regr: 0.2876 - final_cls: 0.5225 - final_regr: 0.3300
215/240 [=========================>....] - ETA: 1:52 - rpn_cls: 1.8464 - rpn_regr: 0.2874 - final_cls: 0.5225 - final_regr: 0.3299
216/240 [==========================>...] - ETA: 1:48 - rpn_cls: 1.8451 - rpn_regr: 0.2872 - final_cls: 0.5225 - final_regr: 0.3300
217/240 [==========================>...] - ETA: 1:43 - rpn_cls: 1.8438 - rpn_regr: 0.2870 - final_cls: 0.5226 - final_regr: 0.3300
218/240 [==========================>...] - ETA: 1:39 - rpn_cls: 1.8424 - rpn_regr: 0.2868 - final_cls: 0.5226 - final_regr: 0.3300
219/240 [==========================>...] - ETA: 1:34 - rpn_cls: 1.8411 - rpn_regr: 0.2867 - final_cls: 0.5226 - final_regr: 0.3300
220/240 [==========================>...] - ETA: 1:30 - rpn_cls: 1.8397 - rpn_regr: 0.2865 - final_cls: 0.5226 - final_regr: 0.3300
221/240 [==========================>...] - ETA: 1:25 - rpn_cls: 1.8384 - rpn_regr: 0.2863 - final_cls: 0.5226 - final_regr: 0.3300
222/240 [==========================>...] - ETA: 1:20 - rpn_cls: 1.8371 - rpn_regr: 0.2861 - final_cls: 0.5226 - final_regr: 0.3300
223/240 [==========================>...] - ETA: 1:16 - rpn_cls: 1.8357 - rpn_regr: 0.2859 - final_cls: 0.5226 - final_regr: 0.3300
224/240 [===========================>..] - ETA: 1:11 - rpn_cls: 1.8343 - rpn_regr: 0.2857 - final_cls: 0.5226 - final_regr: 0.3299
225/240 [===========================>..] - ETA: 1:07 - rpn_cls: 1.8330 - rpn_regr: 0.2856 - final_cls: 0.5226 - final_regr: 0.3299
226/240 [===========================>..] - ETA: 1:02 - rpn_cls: 1.8317 - rpn_regr: 0.2854 - final_cls: 0.5226 - final_regr: 0.3299
227/240 [===========================>..] - ETA: 58s - rpn_cls: 1.8304 - rpn_regr: 0.2852 - final_cls: 0.5226 - final_regr: 0.3299
228/240 [===========================>..] - ETA: 53s - rpn_cls: 1.8291 - rpn_regr: 0.2850 - final_cls: 0.5226 - final_regr: 0.3299
229/240 [===========================>..] - ETA: 49s - rpn_cls: 1.8280 - rpn_regr: 0.2848 - final_cls: 0.5226 - final_regr: 0.3299
230/240 [===========================>..] - ETA: 44s - rpn_cls: 1.8269 - rpn_regr: 0.2847 - final_cls: 0.5226 - final_regr: 0.3299
231/240 [===========================>..] - ETA: 40s - rpn_cls: 1.8258 - rpn_regr: 0.2845 - final_cls: 0.5227 - final_regr: 0.3298
232/240 [============================>.] - ETA: 35s - rpn_cls: 1.8247 - rpn_regr: 0.2843 - final_cls: 0.5227 - final_regr: 0.3298
233/240 [============================>.] - ETA: 31s - rpn_cls: 1.8236 - rpn_regr: 0.2841 - final_cls: 0.5227 - final_regr: 0.3298
234/240 [============================>.] - ETA: 26s - rpn_cls: 1.8225 - rpn_regr: 0.2840 - final_cls: 0.5227 - final_regr: 0.3298
235/240 [============================>.] - ETA: 22s - rpn_cls: 1.8214 - rpn_regr: 0.2838 - final_cls: 0.5227 - final_regr: 0.3298
236/240 [============================>.] - ETA: 17s - rpn_cls: 1.8203 - rpn_regr: 0.2836 - final_cls: 0.5227 - final_regr: 0.3298
237/240 [============================>.] - ETA: 13s - rpn_cls: 1.8194 - rpn_regr: 0.2834 - final_cls: 0.5227 - final_regr: 0.3298
238/240 [============================>.] - ETA: 8s - rpn_cls: 1.8184 - rpn_regr: 0.2833 - final_cls: 0.5227 - final_regr: 0.3298
239/240 [============================>.] - ETA: 4s - rpn_cls: 1.8174 - rpn_regr: 0.2831 - final_cls: 0.5227 - final_regr: 0.3297
240/240 [==============================] - 1072s 4s/step - rpn_cls: 1.8164 - rpn_regr: 0.2829 - final_cls: 0.5227 - final_regr: 0.3297
Mean number of bounding boxes from RPN overlapping ground truth boxes: 9.629166666666666
Classifier accuracy for bounding boxes from RPN: 0.7625
Loss RPN classifier: 1.573888585749231
Loss RPN regression: 0.24293259833551323
Loss Detector classifier: 0.5250074003182817
Loss Detector regression: 0.3263928147032857
Total loss: 2.6682213991063115
Elapsed time: 1071.5359601974487
Total loss decreased from 2.883 to 2.6682213991063115, saving model.
Training complete, exiting.Utvärdering
Denna modul används för att utföra en visuell utvärdering av modellen. Jag har bara tränat modellen i 21 epoker, den här typen av modeller behöver mycket träning för att prestera bra. Resultatet från en utvärdering visas nedanför koden.
# Import libraries
import os
import cv2
import time
import keras
import random
import numpy as np
import matplotlib.pyplot as plt
import annytab.frcnn.common as common
import annytab.frcnn.model_builder as mb
import annytab.frcnn.layers as layers
# The main entry point for this module
def main():
# Create configuration
config = common.Config()
config.img_base_path = 'C:\\DATA\\Python-data\\open-images-v5\\imgs\\'
config.model_path = 'C:\\DATA\\Python-data\\open-images-v5\\frcnn\\training_model.h5'
config.use_horizontal_flips = False
config.use_vertical_flips = False
config.rot_90 = False
config.num_rois = 4
# Set the gpu to use
common.setup_gpu('cpu')
#common.setup_gpu(0)
# Create a dictionary with classes and switch key values
classes = {'Laptop': 0, 'Beer': 1, 'Goat': 2, 'bg': 3}
mappings = {v: k for k, v in classes.items()}
class_to_color = {mappings[v]: np.random.randint(0, 255, 3) for v in mappings}
print(mappings)
# Get inference models
model_rpn, model_classifier, model_classifier_only = mb.get_inference_models(config, len(classes), weights_path=config.model_path)
# Get a list of test images
images = os.listdir(config.img_base_path + 'test')
# Randomize images to get different images each time
random.shuffle(images)
# If the box classification value is less than this, we ignore this box
bbox_threshold = 0.7
# Start visual evaluation
for i, name in enumerate(images):
# Limit the evaluation to 4 images
if i > 4:
break;
# Print the name and start a timer
print(name)
st = time.time()
# Get the filepath
filepath = os.path.join(config.img_base_path + 'test', name)
# Get the image
img = cv2.imread(filepath)
# Format the image
X, ratio = common.format_img(img, config)
X = np.transpose(X, (0, 2, 3, 1))
# Get output layer Y1, Y2 from the RPN and the feature maps F
# Y1: y_rpn_cls
# Y2: y_rpn_regr
[Y1, Y2, F] = model_rpn.predict(X)
# Get bboxes by applying NMS
# R.shape = (300, 4)
R = layers.rpn_to_roi(Y1, Y2, config, keras.backend.image_data_format(), overlap_thresh=0.7)
# Convert from (x1,y1,x2,y2) to (x,y,w,h)
R[:, 2] -= R[:, 0]
R[:, 3] -= R[:, 1]
# Apply the spatial pyramid pooling to the proposed regions
bboxes = {}
probs = {}
for jk in range(R.shape[0]//config.num_rois + 1):
ROIs = np.expand_dims(R[config.num_rois*jk:config.num_rois*(jk+1), :], axis=0)
if ROIs.shape[1] == 0:
break
if jk == R.shape[0]//config.num_rois:
#pad R
curr_shape = ROIs.shape
target_shape = (curr_shape[0],config.num_rois,curr_shape[2])
ROIs_padded = np.zeros(target_shape).astype(ROIs.dtype)
ROIs_padded[:, :curr_shape[1], :] = ROIs
ROIs_padded[0, curr_shape[1]:, :] = ROIs[0, 0, :]
ROIs = ROIs_padded
[P_cls, P_regr] = model_classifier_only.predict([F, ROIs])
# Calculate bboxes coordinates on resized image
for ii in range(P_cls.shape[1]):
# Ignore 'bg' class
if np.max(P_cls[0, ii, :]) < bbox_threshold or np.argmax(P_cls[0, ii, :]) == (P_cls.shape[2] - 1):
continue
# Get the class name
cls_name = mappings[np.argmax(P_cls[0, ii, :])]
if cls_name not in bboxes:
bboxes[cls_name] = []
probs[cls_name] = []
(x, y, w, h) = ROIs[0, ii, :]
cls_num = np.argmax(P_cls[0, ii, :])
try:
(tx, ty, tw, th) = P_regr[0, ii, 4*cls_num:4*(cls_num+1)]
tx /= C.classifier_regr_std[0]
ty /= C.classifier_regr_std[1]
tw /= C.classifier_regr_std[2]
th /= C.classifier_regr_std[3]
x, y, w, h = layers.apply_regr(x, y, w, h, tx, ty, tw, th)
except:
pass
bboxes[cls_name].append([config.rpn_stride*x, config.rpn_stride*y, config.rpn_stride*(x+w), config.rpn_stride*(y+h)])
probs[cls_name].append(np.max(P_cls[0, ii, :]))
all_dets = []
for key in bboxes:
bbox = np.array(bboxes[key])
new_boxes, new_probs = common.non_max_suppression_fast(bbox, np.array(probs[key]), overlap_thresh=0.2)
for jk in range(new_boxes.shape[0]):
(x1, y1, x2, y2) = new_boxes[jk,:]
# Calculate real coordinates on original image
(real_x1, real_y1, real_x2, real_y2) = common.get_real_coordinates(ratio, x1, y1, x2, y2)
cv2.rectangle(img,(real_x1, real_y1), (real_x2, real_y2), (int(class_to_color[key][0]), int(class_to_color[key][1]), int(class_to_color[key][2])),4)
textLabel = '{0}: {1}'.format(key,int(100*new_probs[jk]))
all_dets.append((key,100*new_probs[jk]))
(retval,baseLine) = cv2.getTextSize(textLabel,cv2.FONT_HERSHEY_COMPLEX,1,1)
textOrg = (real_x1, real_y1-0)
cv2.rectangle(img, (textOrg[0] - 5, textOrg[1]+baseLine - 5), (textOrg[0]+retval[0] + 5, textOrg[1]-retval[1] - 5), (0, 0, 0), 1)
cv2.rectangle(img, (textOrg[0] - 5,textOrg[1]+baseLine - 5), (textOrg[0]+retval[0] + 5, textOrg[1]-retval[1] - 5), (255, 255, 255), -1)
cv2.putText(img, textLabel, textOrg, cv2.FONT_HERSHEY_DUPLEX, 1, (0, 0, 0), 1)
print('Elapsed time = {0}'.format(time.time() - st))
print(all_dets)
plt.figure(figsize=(10,10))
plt.grid()
plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB))
plt.savefig('C:\\DATA\\Python-data\\open-images-v5\\frcnn\\plots\\evaluate_' + str(i) + '.png')
#plt.show()
# Tell python to run main method
if __name__ == "__main__": main()