I denna handledning kommer jag att använda Multinomial Naive Bayes och Python för att utföra textklassificering. Jag kommer att använda datauppsättningen 20 nyhetsgrupper, visualisera datauppsättningen, förbereda texten, utföra en rutnätsökning, träna en modell och utvärdera modellens korrekthet.
Naive Bayes är en grupp av algoritmer inom maskininlärning som används för klassificering. Naive Bayes klassificerare grundar sig på Bayes sats, en sannolikhet beräknas för varje kategori och den kategori som har högst sannolikhet är den förutsagda kategorin. Gaussian Naive Bayes behandlar kontinuerliga variabler som antas ha en normalfördelning (gaussisk fördelning). Multinomial Naive Bayes behandlar diskreta variabler som är ett resultat av räkning och Bernoulli Naive Bayes behandlar booleska variabler som är ett resultat av att bestämma om något existerar eller inte.
Multinomial Naive Bayes och Bernoulli Naive Bayes är väl lämpade för textklassificeringsuppgifter. Multinomial Naive Bayes tar hänsyn till det antal ord som förekommer i en text medan Bernoulli Naive Bayes endast tar hänsyn till om ord existerar eller inte. Bernoulli Naive Bayes kan föredras om vi inte behöver den extra komplexitet som erbjuds av Multinomial Naive Bayes.
Datauppsättning och bibliotek
Vi kommer att använda datauppsättningen 20 nyhetsgrupper (ladda ner) i denna handledning. Du ska ladda ner 20news-bydate.tar.gz, denna datauppsättning är sorterad efter datum och delas in i en träningsuppsättning och en testuppsättning. Packa upp filen till en mapp (20news_bydate), filerna är indelade i mappar där mappnamnet representerar namnet på en kategori. Du måste ha följande bibliotek: pandas, joblib, numpy, matplotlib, nltk och scikit-learn.
Förbehandla indata
Jag har skapat en gemensam modul (common.py) som innehåller en funktion för att förbereda data, den här funktionen kommer att anropas från mer än en modul. Mappstrukturen för den här modulen är annytab/naive_bayes och det betyder att namnområdet är annytab.naive_bayes. Denna funktion kommer att behandla varje artikel i datauppsättningen och ta bort sidhuvuden, sidfot, citat, punkteringar och siffror. Jag använder också en ordstämmare, den här processen tar lite tid och du kanske vill kommentera bort den här raden för att snabba upp processen. Du kan använda en ordlemmare istället för en ordstämmare om du vill, du kanske måste ladda ner WordNetLemmatizer.
# Import libraries
import re
import string
import nltk.stem
# Download WordNetLemmatizer
# nltk.download()
# Variables
QUOTES = re.compile(r'(writes in|writes:|wrote:|says:|said:|^In article|^Quoted from|^\||^>)')
# Preprocess data
def preprocess_data(data):
# Create a stemmer/lemmatizer
stemmer = nltk.stem.SnowballStemmer('english')
#lemmer = nltk.stem.WordNetLemmatizer()
for i in range(len(data)):
# Remove header
_, _, data[i] = data[i].partition('\n\n')
# Remove footer
lines = data[i].strip().split('\n')
for line_num in range(len(lines) - 1, -1, -1):
line = lines[line_num]
if line.strip().strip('-') == '':
break
if line_num > 0:
data[i] = '\n'.join(lines[:line_num])
# Remove quotes
data[i] = '\n'.join([line for line in data[i].split('\n') if not QUOTES.search(line)])
# Remove punctation (!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~)
data[i] = data[i].translate(str.maketrans('', '', string.punctuation))
# Remove digits
data[i] = re.sub('\d', '', data[i])
# Stem words
data[i] = ' '.join([stemmer.stem(word) for word in data[i].split()])
#data[i] = ' '.join([lemmer.lemmatize(word) for word in data[i].split()])
# Return data
return dataTräningsmodul
# Import libraries
import joblib
import numpy as np
import matplotlib.pyplot as plt
import sklearn.datasets
import sklearn.feature_extraction.text
import sklearn.naive_bayes
import sklearn.metrics
import sklearn.model_selection
import sklearn.pipeline
import annytab.naive_bayes.common as common
# Visualize dataset
def visualize_dataset(ds):
# Print dataset
#for i in range(5):
# print(ds.data[i])
#print(ds.target_names)
print('--- Information ---')
print('Number of articles: ' + str(len(ds.data)))
print('Number of categories: ' + str(len(ds.target_names)))
# Count number of articles in each category
plot_X = np.arange(20, dtype=np.int16)
plot_Y = np.zeros(20)
for i in range(len(ds.data)):
plot_Y[ds.target[i]] += 1
print('\n--- Class distribution ---')
for i in range(len(plot_X)):
print('{0}: {1:.0f}'.format(ds.target_names[plot_X[i]], plot_Y[i]))
# Plot the balance of the dataset
figure = plt.figure(figsize = (16, 10))
figure.suptitle('Balance of data set', fontsize=16)
plt.bar(plot_X, plot_Y, align='center', color='rgbkymc')
plt.xticks(plot_X, ds.target_names, rotation=25, horizontalalignment='right')
#plt.show()
plt.savefig('C:\\DATA\\Python-models\\accountant\\sklearn\\20-newsgroups-balance.png')
# Perform a grid search to find the best hyperparameters
def grid_search(train):
# Create a pipeline
clf_pipeline = sklearn.pipeline.Pipeline([
('v', sklearn.feature_extraction.text.CountVectorizer(strip_accents='ascii', stop_words='english')),
('t', sklearn.feature_extraction.text.TfidfTransformer()),
('c', sklearn.naive_bayes.MultinomialNB(fit_prior=True, class_prior=None))
])
# Set parameters (name in pipeline + name of parameter)
parameters = {
'v__ngram_range': [(1, 1), (1, 2), (1, 3), (1, 4)],
'v__lowercase': (True, False),
't__use_idf': (True, False),
'c__alpha': (0.3, 0.6, 1.0) }
# Create a grid search classifier
gs_classifier = sklearn.model_selection.GridSearchCV(clf_pipeline, parameters, cv=5, iid=False, n_jobs=2, scoring='accuracy', verbose=1)
# Start a search (Warning: takes a long time if the whole dataset is used)
# Slice: (train.data[:4000], train.target[:4000])
gs_classifier = gs_classifier.fit(train.data, train.target)
# Print results
print('---- Results ----')
print('Best score: ' + str(gs_classifier.best_score_))
for name in sorted(parameters.keys()):
print('{0}: {1}'.format(name, gs_classifier.best_params_[name]))
# Train and evaluate a model
def train_and_evaluate(train):
# Convert to bag of words
count_vect = sklearn.feature_extraction.text.CountVectorizer(strip_accents='ascii', stop_words='english', lowercase=True, ngram_range=(1,1))
X = count_vect.fit_transform(train.data)
# Convert from occurrences to frequencies
# Occurrence count is a good start but there is an issue: longer documents will have higher average count values than shorter documents, even though they might talk about the same topics.
# To avoid these potential discrepancies it suffices to divide the number of occurrences of each word in a document by the total number of words in the document: these new features are called tf for Term Frequencies.
transformer = sklearn.feature_extraction.text.TfidfTransformer()
X = transformer.fit_transform(X)
# Create a model
model = sklearn.naive_bayes.MultinomialNB(alpha=0.3, fit_prior=True, class_prior=None)
# Train the model
model.fit(X, train.target)
# Save models
joblib.dump(count_vect, 'C:\\DATA\\Python-models\\accountant\\sklearn\\vectorizer.jbl')
joblib.dump(transformer, 'C:\\DATA\\Python-models\\accountant\\sklearn\\transformer.jbl')
joblib.dump(model, 'C:\\DATA\\Python-models\\accountant\\sklearn\\model.jbl')
# Evaluate on training data
print('-- Training data --')
predictions = model.predict(X)
accuracy = sklearn.metrics.accuracy_score(train.target, predictions)
print('Accuracy: {0:.2f}'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(train.target, predictions, target_names=train.target_names))
print('')
# Evaluate with 10-fold CV
print('-- 10-fold CV --')
predictions = sklearn.model_selection.cross_val_predict(model, X, train.target, cv=10)
accuracy = sklearn.metrics.accuracy_score(train.target, predictions)
print('Accuracy: {0:.2f}'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(train.target, predictions, target_names=train.target_names))
# The main entry point for this module
def main():
# Load train dataset
# Load text files with categories as subfolder names
# Individual samples are assumed to be files stored a two levels folder structure
# The folder names are used as supervised signal label names. The individual file names are not important.
train = sklearn.datasets.load_files('C:\\DATA\\Python-models\\20news_bydate\\20news-bydate-train', shuffle=False, load_content=True, encoding='latin1')
# Visualize dataset
#visualize_dataset(train)
# Preprocess data
train.data = common.preprocess_data(train.data)
# Print cleaned data
#print(train.data[0])
# Grid search
#grid_search(train)
# Train and evaluate
train_and_evaluate(train)
# Tell python to run main method
if __name__ == "__main__": main()Utvärderingsmodul
# Import libraries
import joblib
import numpy as np
import sklearn.datasets
import sklearn.feature_extraction.text
import sklearn.naive_bayes
import sklearn.metrics
import annytab.naive_bayes.common as common
# Test and evaluate a model
def test_and_evaluate(test):
# Load models
vectorizer = joblib.load('C:\\DATA\\Python-models\\accountant\\sklearn\\vectorizer.jbl')
transformer = joblib.load('C:\\DATA\\Python-models\\accountant\\sklearn\\transformer.jbl')
model = joblib.load('C:\\DATA\\Python-models\\accountant\\sklearn\\model.jbl')
# Convert to bag of words
X = vectorizer.transform(test.data)
# Convert from occurrences to frequencies
X = transformer.transform(X)
# Make predictions
predictions = model.predict(X)
# Print results
print('-- Results --')
accuracy = sklearn.metrics.accuracy_score(test.target, predictions)
print('Accuracy: {0:.2f}'.format(accuracy * 100.0))
print('Classification Report:')
print(sklearn.metrics.classification_report(test.target, predictions, target_names=test.target_names))
# The main entry point for this module
def main():
# Load test dataset
# Load text files with categories as subfolder names
# Individual samples are assumed to be files stored a two levels folder structure
# The folder names are used as supervised signal label names. The individual file names are not important.
test = sklearn.datasets.load_files('C:\\DATA\\Python-models\\20news_bydate\\20news-bydate-test', shuffle=False, load_content=True, encoding='latin1')
# Preprocess data
test.data = common.preprocess_data(test.data)
# Test and evaluate
test_and_evaluate(test)
# Tell python to run main method
if __name__ == "__main__": main()Visualisera datauppsättningen
Koden för visualisering ingår i träningsmodulen. Vi vill främst se balansen i träningsuppsättningen, en balanserad datauppsättning är viktig i klassificeringsalgoritmer. Datauppsättningen är inte perfekt balanserad, den vanligaste kategorin (rec.sport.hockey) har 600 artiklar och den minst frekventa kategorin (talk.religion.misc) har 377 artiklar. Sannolikheten för att korrekt förutsäga den vanligaste kategorin helt slumpmässigt är 5,3% (600 * 100/11314), vår modell måste ha en högre sannolikhet än detta för att vara användbar.
# Load train data set
train = sklearn.datasets.load_files('C:\\DATA\\Python-models\\20news_bydate\\20news-bydate-train', shuffle=False, load_content=True, encoding='latin1')
# Visualize data set
visualize_dataset(train)
--- Information ---
Number of articles: 11314
Number of categories: 20
--- Class distribution ---
alt.atheism: 480
comp.graphics: 584
comp.os.ms-windows.misc: 591
comp.sys.ibm.pc.hardware: 590
comp.sys.mac.hardware: 578
comp.windows.x: 593
misc.forsale: 585
rec.autos: 594
rec.motorcycles: 598
rec.sport.baseball: 597
rec.sport.hockey: 600
sci.crypt: 595
sci.electronics: 591
sci.med: 594
sci.space: 593
soc.religion.christian: 599
talk.politics.guns: 546
talk.politics.mideast: 564
talk.politics.misc: 465
talk.religion.misc: 377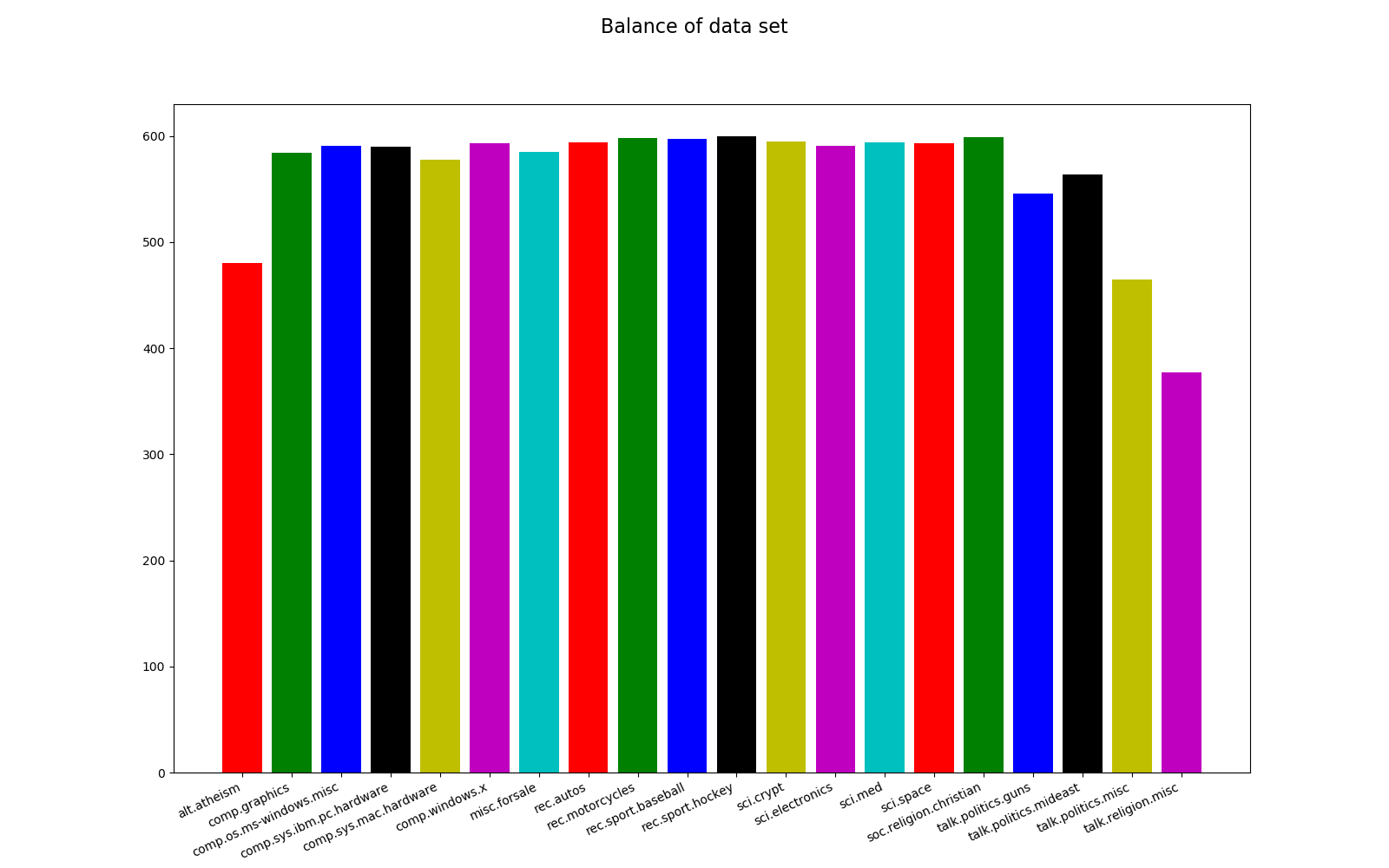
Rutnätssökning
Jag gör en rutnätsökning för att hitta de bästa parametrarna för träning. En rutnätsökning kan ta lång tid att utföra på stora datauppsättningar och du kan därför skiva upp datauppsättningen och utföra rutnätsökningen på en mindre uppsättning. Resultatet från denna process visas nedan och jag kommer att använda dessa parametrar när jag tränar modellen.
Fitting 5 folds for each of 48 candidates, totalling 240 fits
[Parallel(n_jobs=2)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=2)]: Done 46 tasks | elapsed: 2.2min
[Parallel(n_jobs=2)]: Done 196 tasks | elapsed: 10.2min
[Parallel(n_jobs=2)]: Done 240 out of 240 | elapsed: 12.6min finished
---- Results ----
Best score: 0.7087874275996338
c__alpha: 0.3
t__use_idf: True
v__lowercase: True
v__ngram_range: (1, 1)Träna och utvärdera
Jag laddar filer från mappen 20news-bydate-train, jag förbehandlar varje fil och tränar modellen med hjälp av parametrarna från rutnätsökningen, modeller sparas i filer med joblib. Utvärdering görs på träningsuppsättningen och med korsvalidering. Korsvalideringsutvärderingen ger en antydan om modellens generaliseringsprestanda. Jag hade 89,37% exakthet på träningsdata och 71,66% korrekthet med 10-faldig korsvalidering.
# Load train dataset
train = sklearn.datasets.load_files('C:\\DATA\\Python-models\\20news_bydate\\20news-bydate-train', shuffle=False, load_content=True, encoding='latin1')
# Preprocess data
train.data = common.preprocess_data(train.data)
# Train and evaluate
train_and_evaluate(train)
-- Training data --
Accuracy: 89.37
Classification Report:
precision recall f1-score support
alt.atheism 0.95 0.74 0.83 480
comp.graphics 0.93 0.89 0.91 584
comp.os.ms-windows.misc 0.92 0.87 0.89 591
comp.sys.ibm.pc.hardware 0.83 0.93 0.88 590
comp.sys.mac.hardware 0.96 0.89 0.92 578
comp.windows.x 0.94 0.96 0.95 593
misc.forsale 0.96 0.88 0.91 585
rec.autos 0.95 0.88 0.92 594
rec.motorcycles 0.98 0.93 0.96 598
rec.sport.baseball 0.99 0.93 0.96 597
rec.sport.hockey 0.65 0.97 0.78 600
sci.crypt 0.90 0.95 0.92 595
sci.electronics 0.95 0.89 0.92 591
sci.med 0.98 0.95 0.96 594
sci.space 0.97 0.95 0.96 593
soc.religion.christian 0.64 0.98 0.77 599
talk.politics.guns 0.88 0.95 0.91 546
talk.politics.mideast 0.94 0.94 0.94 564
talk.politics.misc 0.98 0.86 0.91 465
talk.religion.misc 1.00 0.30 0.46 377
accuracy 0.89 11314
macro avg 0.92 0.88 0.88 11314
weighted avg 0.91 0.89 0.89 11314
-- 10-fold CV --
Accuracy: 71.66
Classification Report:
precision recall f1-score support
alt.atheism 0.81 0.33 0.47 480
comp.graphics 0.72 0.66 0.69 584
comp.os.ms-windows.misc 0.74 0.60 0.66 591
comp.sys.ibm.pc.hardware 0.61 0.74 0.67 590
comp.sys.mac.hardware 0.78 0.71 0.75 578
comp.windows.x 0.80 0.85 0.82 593
misc.forsale 0.82 0.67 0.73 585
rec.autos 0.81 0.72 0.76 594
rec.motorcycles 0.81 0.73 0.77 598
rec.sport.baseball 0.91 0.81 0.86 597
rec.sport.hockey 0.59 0.90 0.71 600
sci.crypt 0.64 0.87 0.74 595
sci.electronics 0.78 0.69 0.73 591
sci.med 0.88 0.82 0.85 594
sci.space 0.83 0.78 0.80 593
soc.religion.christian 0.43 0.94 0.59 599
talk.politics.guns 0.68 0.81 0.74 546
talk.politics.mideast 0.81 0.82 0.81 564
talk.politics.misc 0.86 0.49 0.63 465
talk.religion.misc 0.58 0.04 0.07 377
accuracy 0.72 11314
macro avg 0.74 0.70 0.69 11314
weighted avg 0.75 0.72 0.71 11314Testa och utvärdera
Testning och utvärdering görs i utvärderingsmodulen. Jag laddar filer från mappen 20news-bydate-test, jag förbereder testdata, jag läser in modeller och jag utvärderar korrektheten. Jag laddar in 3 modeller, en CountVectorizer, en TfidfTransformer och en MultinomialNB-modell. Resultatet från utvärderingen visas nedan.
# Load test dataset
test = sklearn.datasets.load_files('C:\\DATA\\Python-models\\20news_bydate\\20news-bydate-test', shuffle=False, load_content=True, encoding='latin1')
# Preprocess data
test.data = common.preprocess_data(test.data)
# Print cleaned data
print(test.data[0])
# Test and evaluate
test_and_evaluate(test)
-- Results --
Accuracy: 67.83
Classification Report:
precision recall f1-score support
alt.atheism 0.75 0.24 0.36 319
comp.graphics 0.66 0.66 0.66 389
comp.os.ms-windows.misc 0.72 0.54 0.62 394
comp.sys.ibm.pc.hardware 0.59 0.72 0.65 392
comp.sys.mac.hardware 0.75 0.68 0.71 385
comp.windows.x 0.80 0.76 0.78 395
misc.forsale 0.82 0.68 0.74 390
rec.autos 0.83 0.74 0.78 396
rec.motorcycles 0.83 0.73 0.78 398
rec.sport.baseball 0.94 0.81 0.87 397
rec.sport.hockey 0.59 0.94 0.72 399
sci.crypt 0.60 0.80 0.69 396
sci.electronics 0.69 0.55 0.61 393
sci.med 0.86 0.78 0.82 396
sci.space 0.76 0.77 0.77 394
soc.religion.christian 0.39 0.92 0.55 398
talk.politics.guns 0.54 0.72 0.62 364
talk.politics.mideast 0.80 0.80 0.80 376
talk.politics.misc 0.80 0.34 0.48 310
talk.religion.misc 0.75 0.01 0.02 251
accuracy 0.68 7532
macro avg 0.72 0.66 0.65 7532
weighted avg 0.72 0.68 0.67 7532